时间与比特币价格之间是否存在关系
-
本文探讨了时间与比特币价格之间是否存在关系。针对最小二乘假设,对提出的双对数(log-log)模型[1,2&3]进行了统计有效性检验,使用Engle-Granger方法进行协整,以确保每个变量的平稳性以及潜在的虚假关系。 除了这些测试中的一种以外,所有测试都可以反驳时间是比特币价格一种重要预测因素的假设。
各种来源[1、2和3]提出了对数价格〜对数时间(又名对数增长)模型来解释比特币价格走势的很大一部分,因此提出了一种估计未来比特币价格的机制。
科学方法对大多数人都是很难理解。 这是违反直觉的。 它可能会得出不反映个人信念的结论。 理解这个基本的基本概念是该方法的基础:错误是可以接受的。
根据伟大的现代科学哲学家卡尔·波普尔(Karl Popper)的观点,为一种错误的结果检验一种假设是增加论点正确性的唯一可靠方法。 如果严格和重复的测试不能表明假设是不正确的,则对于每个测试,假设都具有较高的正确性。 这个概念称为可证伪性。 本文旨在伪造比特币价值的对数增长模型,该模型在[1、2和3]中进行了基本定义。
注:
所有分析均使用Stata 14执行。 本文不充当财务建议。
定义问题
为了伪造一个假设,首先我们必须说明它是什么:
空假设(H0):比特币的价格是比特币已存在天数的函数
替代假设(H1):比特币的价格不是比特币存在天数的函数
[1、2和3]的作者选择通过在比特币价格的自然对数和比特币存在天数的自然对数上拟合普通最小二乘(OLS)回归来测试H0。 两个变量都没有伴随的诊断程序,也没有任何确定的对数转换推理。 该模型没有考虑由于非平稳性造成的虚假关系的可能性,也没有考虑任何相互作用或其他混杂因素的可能性。
方法
在本文中,我们将探索该模型并通过常规回归诊断对其进行运行,并确定对数转换是否必要或适当(或两者),并探讨可能的混淆变量,交互作用以及对混淆的敏感性。
另一个将要探讨的问题是非平稳性。 平稳性是大多数统计模型的假设。 这个概念即随着时间的流逝,任何时刻都没有趋势,例如,相对于时间的均值(或方差)没有趋势。
在平稳性分析之后,我们将探讨协整的可能性。
符号
介质在数学符号方面相对有限。估计统计参数的常用符号是在上面放一个范围。相反,我们将术语的估计定义为[]。例如β的估计值= [β]。如果我们表示一个2x2矩阵,我们将像[r1c1,r1c2 r2c1,r2c2]等进行操作。下标术语被@取代-例如,对于向量X中的第10个位置,我们通常将X下标10。我们写成X @ 10。
普通最小二乘
普通最小二乘回归是一种估计两个或多个变量之间线性关系的方法。
首先,让我们将线性模型定义为X的某个函数,该函数等于Y且存在一些误差。
Y =βX+ε
其中Y是因变量,X是自变量,ε是误差项,β是X的乘数。OLS的目标是估计β,以使ε最小。
为了使[β]成为可靠的估计,必须满足一些基本假设(称为高斯-马可夫假设[4]):
- 因变量和自变量之间存在线性关系
- 这些错误是同调的(也就是说,它们具有恒定的方差)
- 误差的平均分布为零
- 错误中没有自相关(也就是说,错误与错误的滞后无关)
我们首先看一下价格v天的非变换散点图(来自Coinmetrics的数据)。
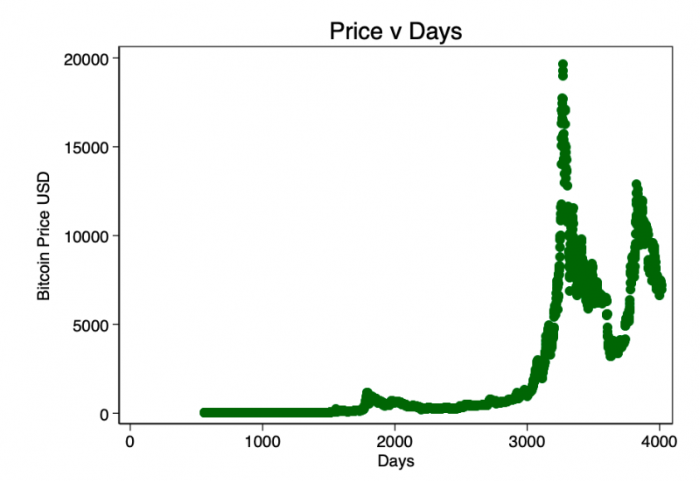
图1-价格v天。 数据分布范围太广,无法通过视觉确定线性度。
在图1中,我们遇到一个很好的理由来获取价格的对数——跨度太宽了。 取价格的对数(而不是天)并重新绘图,使我们形成了熟悉的对数显示模式(图2)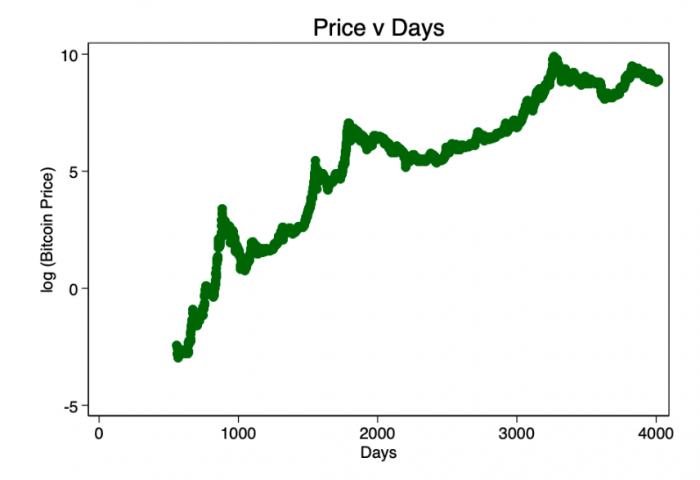
图2-日志价格v天。 一个清晰的对数模式正在出现。
取几天的对数并再次作图,得出了由图3中[1、2和3]的作者确定的明显线性模式。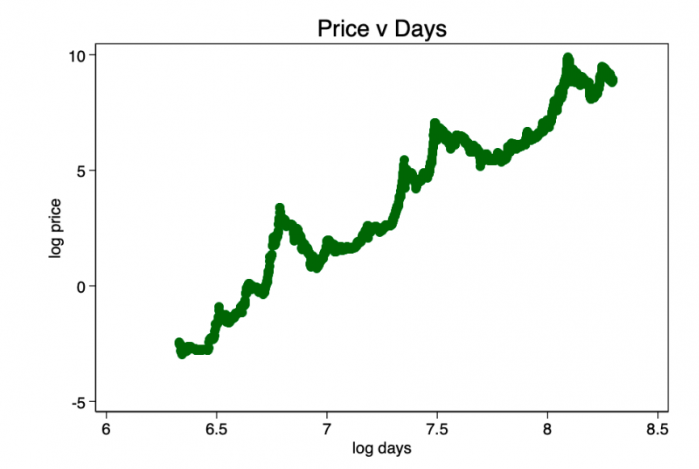
图3 —明显的线性关系出现了
这证实了对数-对数的选择——唯一真正显示出良好线性关系的转换。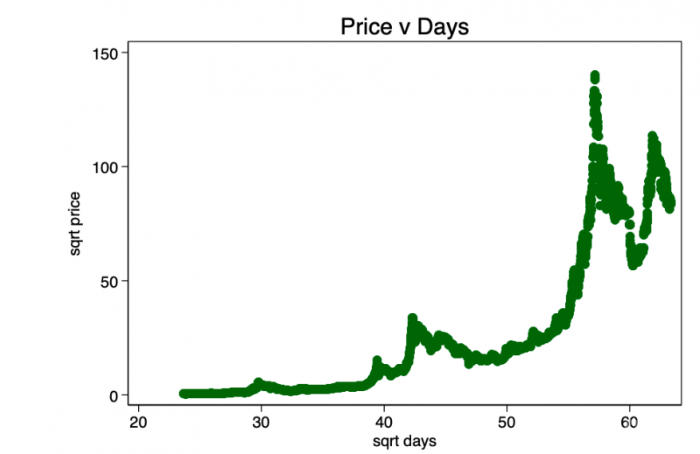
图4 –平方根变换比未变换的序列好很多
因此,初步分析不能否定H0。对数-对数拟合回归在下面的图5中给出,其中[β] = 5.8

图5 —对数-对数回归结果
使用该模型,我们现在可以估计残差[ε]和拟合值[Y]并测试其他假设。同质性
如果误差项中恒定方差的假设(即同心平稳性)为真,则对于预测值中的每个值,误差项将在0附近随机变化。 因此,RVF图(图6)是研究此假设准确性的简单而有效的图形方法。 在图6中,我们看到有一个巨大的模式,而不是随机的散射,表明误差项的非恒定方差(即异方差)。
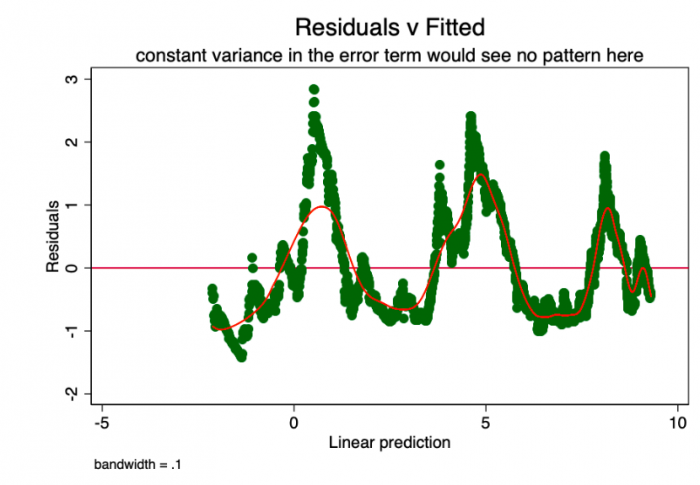
图6a-RVF图。 此处的模式表示存在问题。
像这样的异方差性会导致系数[β]的估计值具有较大的方差,因此精度较低,并导致p值比应有的值大得多,这是因为OLS程序无法检测到增大的方差。 因此,当我们然后计算t值和F值时,我们使用了方差的低估值,从而导致较高的显着性。 这也会对[β]的95%置信区间产生影响,该区间本身是方差的函数(通过标准误差)。自相关的Breusch-Godfrey [6&7]统计量也很重要,进一步为该问题提供了证据。

图6b-检测到的残差中的自相关
在这个阶段,通常是我们停止并重新指定模型的时候。 但是,鉴于我们知道这些问题的影响,因此继续进行回归分析以了解存在这些问题将相对安全。 我们可以通过多种方式来处理这些问题中的(轻度形式),例如自举或使用健壮的估计器作为方差。
图7 —不同估计显示了异方差的影响
如图7所示,尽管方差有小幅增加(请参见扩大的置信区间),但在大多数情况下,存在的异方差实际上并没有太大的有害影响。误差中的正常性
误差项服从零均值正态分布的假设比线性或同方差不那么重要。 非正态但不偏斜的残差将使置信区间过于乐观。 如果残差偏斜,那么您可能最终会有一点偏差。 从图8和9中可以看到,残差严重倾斜。 Shapiro-Wilk正态性检验的p值为0。它们不完全符合正态曲线,因此置信区间不受影响。
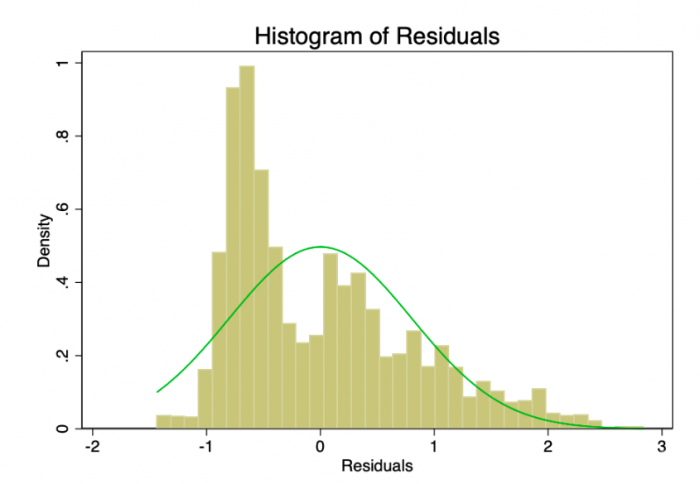
图8-误差项的直方图,正态分布(绿色)覆盖。 这个误差项应该是正常的,但事实并非如此。
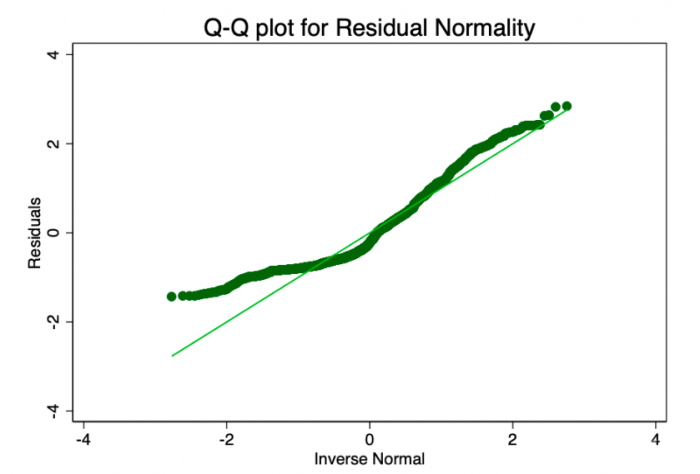
图9-误差项的正常分位数图。 点越接近直线,法线拟合越好。
杠杆作用杠杆的概念是,并非回归中的所有数据点都对系数的估计有同等的贡献。 某些具有高杠杆作用的点可能会根据是否存在来显着改变系数。 在图10中,我们可以很清楚地看到,涉及点数太多(平均剩余金额以上且平均杠杆以上)。
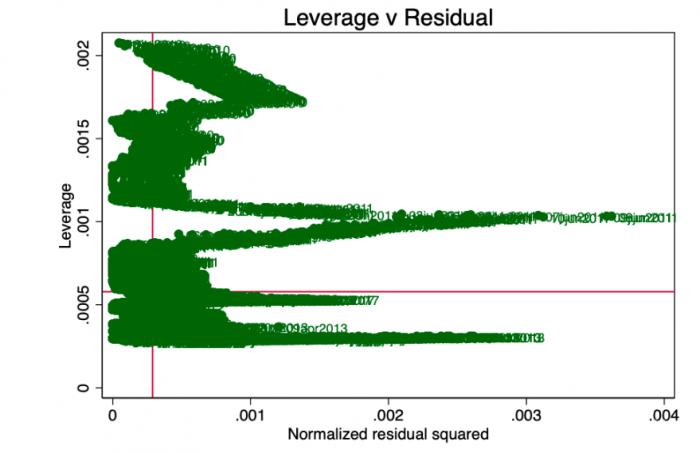
图10-利用v平方残差。
最小二乘(OLS)摘要基本诊断表明除了线性以外,基本上违反了所有高斯-马尔可夫(Gauss-Markov)假设。 这是拒绝H0的相对有力的证据。
稳定状态
平稳过程被称为集成了0级(例如I(0))。 非平稳过程为I(1)或更大。 在这种情况下,集成更像是穷人的集成——它是滞后差异的总和。 I(1)表示,如果我们从序列中的每个值中减去第一个滞后,我们将有一个I(0)过程。 相对众所周知,对非平稳时间序列的回归可以导致虚假关系的识别。
在下面的图12和图13中,我们可以看到我们不能拒绝增强迪基·富勒(ADF)检验的零假设。 ADF检验的零假设是数据不稳定。 这意味着我们不能说数据是固定的。
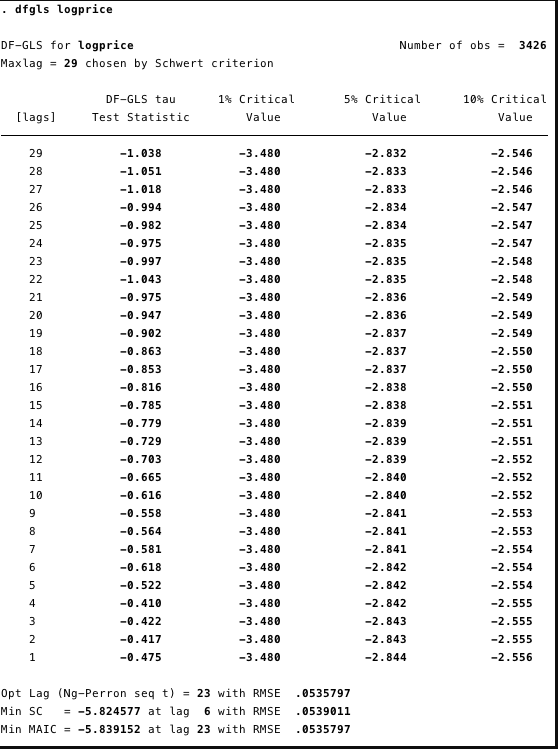
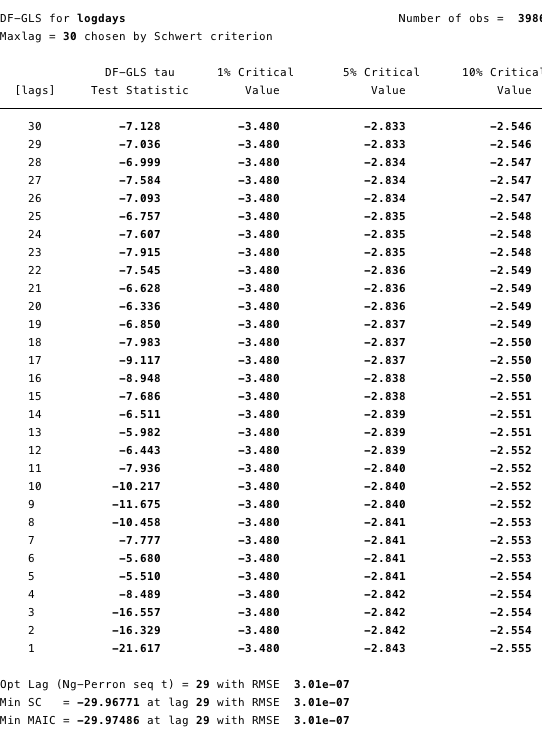
图11和12 – GLS增强了ADF测试,以记录价格和记录天数为单位根。
Kwiatkowski-Phillips-Schmidt-Shin(KPSS)测试是对ADF测试的平稳性的补充测试。 该测试具有零假设,即数据是固定的。 如图13和14所示,我们可以拒绝两个变量中大多数滞后的平稳性。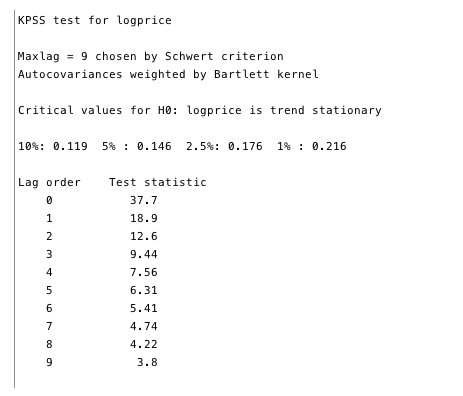
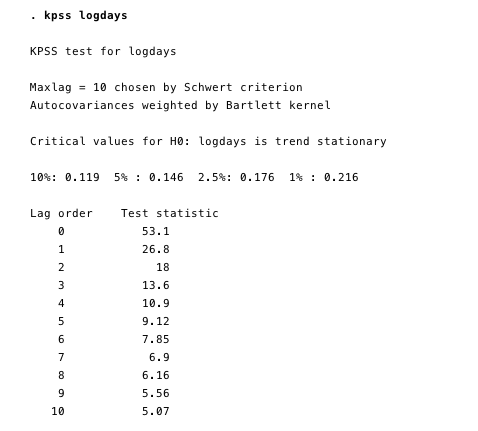
图13和图14 —针对平稳性无效的KPSS测试
这些测试证明这两个系列无疑是平稳的。 这有点问题。 如果该序列至少不是趋势平稳的,那么OLS可能会误导您识别虚假关系。 我们可以做的一件事是获取每个变量的对数日差并重建我们的OLS。 然而,由于此问题在计量经济学系列中相当普遍,因此我们可以使用更强大的框架——称为协整。协整
协整是一种处理一对(或多个)I(1)进程并确定是否存在关系以及该关系是什么的方法。 为了理解协整,我们举了一个醉汉和她的狗的简化例子[3]。 想象一下,一个醉汉用皮带牵她的狗回家。 醉汉在各处走来走去, 这只狗也随机行走:嗅树,吠叫,追逐抓挠。 但是,狗的总体行进方向将在醉酒者的牵引带范围内。 我们可以估计,在醉汉步行回家的任何地方,狗都会在醉汉的皮带长度之内(确保它可能在一侧或另一侧,但狗一定在皮带长度之内)。 这种糟糕的简化是对协整的一个粗略比喻——狗和主人一起移动。
将其与相关性进行对比——假设流浪狗沿着醉酒走了95%的回家路程,然后跑去追着汽车驶向城镇的另一侧。 流浪者与行走行径之间将有很强的相关性(字面意思是R²:95%),但是就像醉汉拥有许多晚上的床头柜——这种关系并不意味着任何东西——它不能用来预测醉酒的出行地点,而在旅途的某些部分中,这是事实,而在某些部分中,这是完全不正确的。
为了找到醉汉,首先,我们将看到我们的模型应使用什么滞后规范。
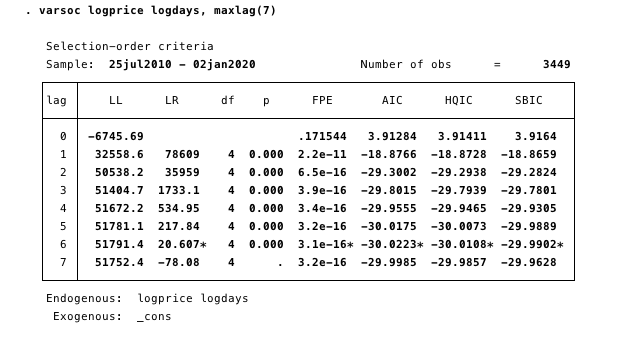
图15-延迟阶数说明。 最小AIC用于确定。
我们在这里确定通过选择最小AIC进行调查的最合适的滞后阶数为6。接下来,我们需要确定是否存在协整关系。 简单的Engle-Granger框架[8,9,10]使此操作相对容易。 如果测试统计量比临界值更负,则存在协整关系。
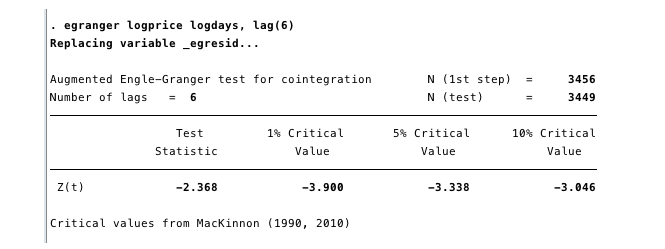
图16 —测试统计量远没有小于任何临界值
图16中的结果没有证据表明对数价格与对数天之间存在协整方程。局限性
在这项研究中,我们没有考虑任何混杂变量。 鉴于以上证据,任何混杂因素都不太可能对我们的结论产生重大影响-我们可以拒绝H0。 我们可以说“日志天数和日志比特币价格之间没有关系”。 如果真是这样,那么就会有一个共同的关系。
结论
鉴于违反了所有高斯马尔科夫(Gauss Markov)假设的有效线性回归假设,并且没有可检测到的协整性,并且两个变量都是非平稳的,因此有足够的证据拒绝H0,因此没有有效的线性回归。 对数价格和对数天数之间的线性关系,因此不能用来可靠地预测样本估计价格。
区块链技术是近几年大受欢迎的一种新型技术
它的出现给我们带来了许多有益的变化和改进。区块链技术的出现在一定程度上,改变了我们的货币体系、商业支付系统、电子商务和信息交互的方式等。区块链对于许多行业有所帮助:
首先,在金融行业,区块链技术可以改变金融服务的方式,改善和提高金融服务质量,并且允许更多的金融机构进行跨境金融业务。区块链也有助于实现实时金融结算,以期节省管理成本和提高效率。
其次,区块链技术还有助于智能合约的发展。智能合约将在未来扮演一个重要的角色,可以有效地解决由交易双方异议引起的各种合同法律问题。另外,智能合约也可以作为传统合同的替代品,在降低交易成本和提高效率的同时,保护双方的利益和权利。
此外,区块链也可以用于政府管理中,以帮助处理大规模的数据,并确保数据安全性、完整性和可追溯性。同时,还可以用于政府间的信任协议实现,以消除不必要的繁琐的政策程序,从而提高政府事务办理的效率。
最后,区块链技术还可以应用于健康医疗和安全许可证领域,以最大限度地解决健康和安全相关的问题。使用区块链技术,可以实现快速的医疗信息查询和共享,以及快速的和实时的安全许可追踪、评估和管理,从而大大减少人力资源的投入。
总之,区块链技术对于不同行业的发展具有巨大的催化作用,在诸如金融、智能合约、政府管理、健康和安全等行业都有着巨大的帮助。通过对记录、政策追踪、数据安全性和完整性的优势,区块链技术能够改变以便令传统业务更加高效、安全、可靠。
- 比特币价格


下一篇
严锋:万众争说元宇宙
-

- 币王
- 2023-07-05
- 12738
- 严锋:复旦大学中文系教授、科学杂志《新发现》主编 一个幽灵,元宇宙的幽灵,在人类世界游荡。一时间,万众争说元宇宙,无数企业想戴上元宇宙这顶帽子。有人欢喜有人忧,有人认为元宇宙是未来,有人认为是泡沫,还有人认为是毒品,会腐蚀人的心灵,甚至会把人类引向万劫不复的深渊。
24小时热点
热点专题

 2320904
2320904 







