
模型参数是什么意思
-
模型参数是数据特征量及其模型结构的不同变量,所有参数在一起使用,每个参数都起着重要作用,可以在模型中进行改变以及调整。模型参数是机器学习模型的基础,它们可以是人为设置的参数,也可以由学习算法本身决定。
模型参数是机器学习模型的基本单位,众多参数一起工作,可以为模型控制输出的结果。模型参数可以通过调整来提高或降低模型的准确性和精确度。有些参数用于控制模型的学习率,有些参数用于控制模型的正则化,有些参数用于控制模型的偏差,有些参数用于控制模型的复杂度,还有其它参数可供控制。
除了具体的参数,模型可以有几种构造:模型的复杂度,层次,大小等。要定义模型参数,首先要为数据集选择合适的数据结构,将数据集分成输入和输出,然后定义模型的结构及其参数,可以使用梯度下降法来更新参数。(认准国际大站欧易,官网注册,APP下载)
模型参数的设定会影响模型的准确度,过大或过小的参数都可能引发模型偏差的问题,模型准确度会下降。因此,更新模型参数必须以适当的形式进行,而且需要注意到正则化参数。
以及其他决定模型准确度的关键参数,如L2正则化参数、dropout等,都不得不考虑,以保证模型免受过拟合影响,确保其可以正确地推进它学习的任务。
总而言之,模型参数是机器学习模型的重要组成部分,巧妙的参数设置可以提出模型的准确度和有效性,因此了解模型参数设置以及使用遍历方法进行参数调整的重要性,对于设计,调试,实施和管理机器学习系统的质量至关重要。
提醒大家务必要注意!现在币圈和链圈也存在诈骗的情况:现在区块链方面的项目太火了,国内外各类传销、资金盘都打着“金融创新”“区块链”的旗号,通过发行所谓“虚拟货币”“虚拟资产”“数字资产”等方式吸收资金,侵害公众合法权益。此类活动并非真正基于区块链技术,而是炒作区块链概念行非法集资、传销、诈骗之实。请大家务必要警惕!还要警惕各类交易所小平台,必须选择全球知名的品牌。

大模型不是人人玩得起的
大模型门槛比较高,具体表现为参数大、数据大、算力大
参数:语言大模型的参数规模亿级~万亿级(BERT作为baseline),图像大模型参数规模在亿级~百亿级范围。模型参数越大,代表着需要存储模型空间也越变大,需要的成本也就越高。
模型参数是什么?
aX1+bX2=Y,X1和X2是变量,Y是计算结果,a和b是参数,同理,一个神经网络模型,无论规模多大,它都是一个函数,只不过这个函数极其复杂,维度极其多,但依然是由参数、变量来组成,我们通过数据来训练模型,数据就是变量,而参数,就是通过变量的变换,学到的最终的常量。
5年内,模型参数数量从亿级别发展到100万亿级,增长100万倍
数据:模型参数的大幅增长,必然需要更大的数据来训练,否则模型强大的表征能力就会轻易地过拟合。由于标注成本和训练周期的限制,传统有监督的方式将变得不现实,因此无法全用标注好的监督数据,需要利用自监督的方法,挖掘数据中的信息。从18年BERT的33亿词符,到19年XLNet的330亿词符,20年GPT-3的6800亿词符,数据量以十倍速度增长(英文数据集大小也差不多止于此),22年PaLM 使用了7800亿词符训练。

不同大模型预训练数据集规模(大小:GB)的增长对比
算力:尽管“小模型”阶段对算力的要求就一直持续增长,但那个阶段可以说用1张GPU卡可以解决,也算不上太夸张,很多个体,小企业也都可以玩,但是到了超大规模预训练模型阶段,超大的参数、数据带来对算力的要求,是普通玩家难以企及的。就算构建了网络结构,获取到了数据,但是算力不行,也训练不起来。从算力需求的角度看,从GPT的18k petaFLOPs,到 GPT-3的310M petaFLOPs,以及PaLM的2.5B petaFLOPs,更直观的可以看下面这张图。从成本的角度,感受大模型训练对算力成本的吞噬——GPT-3的训练使用了上万块英伟达v100 GPU,总成本高达2760万美元,个人如果要训练出一个PaLM也要花费900至1700万美元。
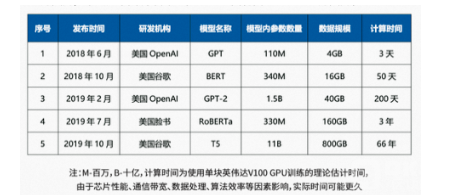
典型的大模型例如GPT BERT GPT-2等的训练时间





24小时热点









热点专题

 4225595
4225595





