
去中心化数据存储
-
本文涵盖了去中心化身份的核心概念、互联网上身份的演变、Web3 身份基础设施栈的逐层概述以及隐私原语的相关发展情况。我们会在未来的文章中探讨人格证明、合规性以及应用层。

Web3 身份基础设施——2022 年 12 月
身份是由与个人、实体或物体相关数据所组成的新兴属性。在现实世界中,它是我们在脑海中根据他人声誉及自我联想形成的一种思维概念;而在数字世界中,身份由两个部分组成:
· 身份标识:用于识别单一主体的一组字符或数字(如护照号码、Twitter ID、学生 ID)
· 与该主体有关的数据(如旅行历史、发推量和关注量、学术成就等等)
为互联网创建一个身份层往往并不简单,因为人们对它的具体含义和运作方式缺乏共识。数字身份离不开情境,我们在网络上对于不同内容的差异体验往往也是建立在各类的情境之上。今天,我们大部分的数字身份不仅支离破碎,而且受到少数人的控制,他们不想让这些身份脱离自己的情境。
· 企业将客户关系视为关键资产,不愿意放弃对这些关系的控制。到目前为止,它们也还没有找到这样做的合理理由,毕竟即使是临时身份也比它们无法控制的框架要好。
· 当涉及到维护与客户和供应商的线上关系时,金融这类特定行业往往有独特的需求(如合规)。
· 政府有区别于其他类型组织的需求,例如,它们对驾驶执照和护照有着管理权。
这种模式让管理我们身份与数据的各方之间有了不同的权力划分。它限制了我们的自主权,让我们无法选择性地披露自己的信息,并在不同的环境中转移自己的身份,自然也就很难获得线上/线下的一致体验。
在 Crypto 和 Web3 兴起之前,去中心化的身份已经获得了不小的关注。其目标是让个人重新获得对其身份的自主权,而无需再依赖中心化的组织。与此同时,客户数据的滥用以及人们对大公司信任程度的减弱,也让去中心化成为了下一个互联网身份时代的核心要素。

去中心化身份的核心概念
去中心化身份标识(DID)和证明是去中心化身份的主要组成部分。DID 会发布并存储在可验证的数据注册处(VDR),它是不受中心化管理的自主「命名空间」。除了区块链之外,去中心化的存储基础设施和 P2P 网络也可以作为 VDR。
在这里,各类实体(个人、社区、组织)可以使用去中心化的公钥基础设施(PKI)来认证、证明所有权,并管理他们的 DID。与传统的网络 PKI 不同的是,它不依赖于中心化的证书机构(CA)作为其信任根(RoT)。
有关身份的数据会被写成证明——它们是一个身份对另一个身份(或他们自己)所作出的「声明」。我们可以通过 PKI 实现的 Crypto 签名来完成对这些声明的验证。
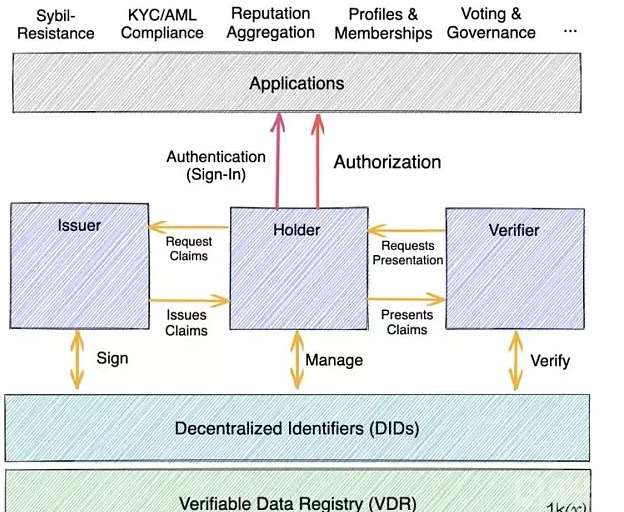
去中心化身份标识有 4 个主要属性:
· 去中心化:其创建不依赖于中心化机构,各实体可以依据不同的环境自主创建相应的身份标识,以实现不同身份、角色和互动情况的分离。
· 永久性:一经创建就永久地归属于实体(虽然有些 DID 是为短暂的身份设计的)。
· 可解析性:可以用来揭示有关该实体的额外信息。
· 可验证性:由于有了 Crypto 签名和证明,实体可以证明 DID 的所有权或声明(可验证凭证),而无需依赖第三方。
这些属性将 DID 与其他身份标识区分开来,如用户名(不可验证)、护照(不可去中心化)和区块链地址(持久性、可解析性有限)。
万维网联盟(W3C)是一个由不同组织、工作人员和公众组成的国际社区,共同致力于开发网络标准。W3C 的DID Spec定义了 4 个主要组成部分:
· 体系:前缀「did」将告诉其他系统它正在与 DID 进行交互,而不是其他类型的身份标识,如 URL、电子邮件地址或产品条形码。
· DID 方法:向其他系统指定如何解释该身份标识。W3C 网站上列出了 100 多种 DID 方法,通常与它自己的 VDR 有关,并有不同的机制来创建、解析、更新和停用身份标识。
· 唯一身份标识:一个特定于 DID 方法的唯一标识,例如某特定区块链上的地址。
· DID 文件:上述 3 个部分可以解析为 DID 文件,其中包括实体可以自我认证的方式,有关实体的任何属性/声明,以及实体额外数据存放地点的指示符(「服务端点」)。
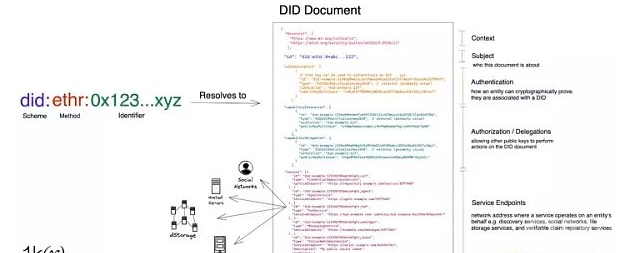
去中心化身份标识和 DID 文件的解析
Crypto 之作用
虽然公钥基础设施(PKI)已经存在了很长时间,但 Crypto 通过 Token 网络的激励机制加速了它的采用。Crypto 曾经主要由注重隐私的技术专家使用,现在已经成为了参与新经济的先决条件。用户需要创建钱包来自我保管他们的资产,并与 Web3 应用程序互动。在 ICO 浪潮、DeFi 之夏、NFT 热潮和 Token 化社区的推动下,用户拥有了比以往更多的密钥。随之而来的是一个充满活力的产品和服务生态系统,大大提高了密钥管理的便捷性和安全性。可以说,Crypto 为去中心化身份基础设施及其采用提供了坚实的基础。
我们可以先来探探钱包,虽然钱包主要还是扮演着资产管理的功能,但 Token 化的实现以及链上历史记录已经能让我们展示自己的兴趣(NFT 收藏)、工作(Kudos,101)和意见(治理投票)。私钥的丢失已经不仅限于金钱的损失,而已经更类似于护照或社交账号的丢失了。所以说,加密逐渐模糊了我们的个人身份与持有物品之间的界限。

不过,我们的链上活动与持有物只能部分反映我们的身份。区块链只是去中心化身份栈的其中一层,其他层将有助于解决一些重要的问题,比如:
· 我们如何在网络和生态系统中识别和认证自己的身份?
· 我们如何在保护个人隐私的同时证明一些事情(声誉、独特性、合规性)?
· 我们如何授予、管理和撤销对我们数据的访问?
· 我们在能够掌控自己的身份与数据的情况下与应用程序互动?
这些问题的解决方案对未来的互联网影响深远。
在下面几节中,我将逐层概述 Web3 的身份栈,即可验证的数据注册、去中心化存储、数据的可变性和可组合性、钱包、认证、授权和证明。
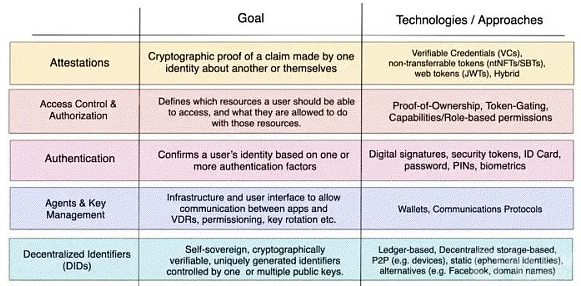
去中心化身份基础设施栈
Web3 身份栈
区块链作为可验证的数据登记处
区块链的分布式特性和不可变性使其适合作为可验证的数据登记处,用于发布 DID。事实上,各种公链都有 W3C 的 DID 方法,例如:
· Ethereum,其中 did:ethr:代表 Ethereum 账户的身份
· Cosmos,其中 did:cosmos:::代表一个 Cosmos 链间兼容的资产
· Bitcoin,其中 did:btcr: 代表一个 TxRef 编码的交易 ID,参考基于 UTXO 的比特币区块链中的交易位置
值得注意的是,did:pkh:
是一种与账本无关的生成性 DID 方法,旨在实现区块链网络的互操作性。根据 CAIP-10 标准,是账户 ID,用于跨链的密钥对表达。Fractal 是一个身份配置和验证协议,用于需要独特和不同级别 KYC 用户的应用。在完成有效性和 KYC 检查后,Fractal DID 会被发布到相应的 Ethereum 地址上,并添加到相应的列表中。Fractal 的 DID 注册表是 Ethereum 上的一个智能合约,交易方可以根据该合约查询 Fractal DID 及其验证级别。
Kilt、Dock 和 Sovrin是用于自我主权身份的特定应用区块链。在撰写本文时,它们主要被企业用来向终端用户发放身份和凭证。为了参与网络,节点需要质押本地 Token 来处理交易(如 DID/凭证的发行)、定义凭证模式,并执行撤销更新。
去中心化数据存储
虽然通用区块链也可以作为资产所有权和交易历史等不可改变类用户数据的数据源(例如用于投资组合追踪器和「DeFi score」应用程序),但它们可能不适合于存储用户的大部分数据,因为编写并定期更新大量信息的成本相当高昂,并且其数据可见性还会危及个人隐私。
即便如此,Arweave 这样特定于应用的区块链还是为永久存储而设计的。为了复制网络上存储的信息,Arweave 会向矿工支付区块奖励和交易费用。矿工需要提供「访问证明」(Proof-of-Access),以便增加新的区块。Arweave 将把一部分费用交给一个永久性的资助基金,将来当通胀和费用不足以支付存储成本时,该基金将把这部分钱付给矿工。
Etherum 和 Arweave 都是基于区块链的数据永久储存方案。在 Ethereum 上,每个全节点必须存储整条链的数据;而在 Arweave 上,处理新区块和新交易所需的所有数据都被记入每个单独区块的状态中,新的参与者只需从其受信任的同伴那里下载当前区块即可加入网络。
基于合约的持久性表明,数据不能被每个节点永久地复制和存储。相反,数据可以通过在多个节点上部署合约来实现持久性。这些节点会在一段时间内持有某项数据,并且每当他们用完后必须续约,以保持数据的持久性。
IPFS 允许用户在一个点对点的网络中存储和传输可验证、有内容地址的数据。用户可以在自己的 IPFS 节点上保存他们想要的数据,使用专门的节点组或第三方的固定服务,如 Pinata、Infura 或 Web3.storage。只要有一个节点在存储数据,数据就存在于网络中,并且可以在其他节点有需求时提供给它们。IPFS 的顶层是 Crypto 经济层,如 Filecoin 和 Crust Network,旨在通过创建一个长期数据持久性的分布式市场来激励网络的数据存储。
对于个人身份信息(PII),受许可的 IPFS 可以用来遵守 GDPR/CCPA 的被遗忘权,因为它允许用户删除他们存储在网络中的数据。身份钱包 Nuggets 采用了这种方法,它通过让商家和合作伙伴运行专门的节点从而进一步实现了去中心化。
Sia 和 Storj 是另外两个基于合约的去中心化存储解决方案,它在整个网络的多个节点之间加密和分割单个文件。两者都使用擦除编码(只需要一个存储节点的子集来提供文件),以确保数据可以在一些节点离线时保持可用;并且都有内置的激励结构,可供人们使用原生 Token 进行存储。
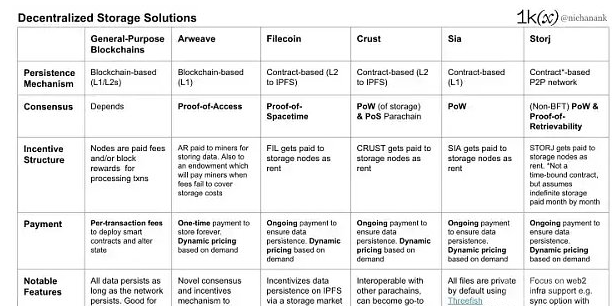
数据突变与可组合性
通用区块链、Arweave 和 IPFS 都保证了数据的不变性,这对静态 NFT 艺术品和永久记录等数据来说非常重要。然而,我们今天与大多数应用程序的交互活动会不断地更新我们的数据。为可变数据设计的 Web3 协议就是为了实现这一点而创建的,它充分利用了底层的去中心化存储层。
Ceramic 是一种去中心化数据突变与可组合性协议,它通过从 IPFS 或者 Arweave 这样的持久性数据存储网络获取不可变的文件,并将它们转换成动态数据结构。在 Ceramic 中,这些「数据流」类似于它自己的可变分类账。私人数据可以通过在 Ceramic 上建立索引进行链外存储,附加到通往外部私人存储的 DID 数据存储上。
当用户在一个由 Ceramic 驱动的应用程序中更新他们的资料时,该协议会将这些更新验证到一个流文件中,将其转化为一个新的状态,同时保持对以前状态变化的跟踪。Ceramic 上的每一个更新都由一个可以映射到多个地址的 DID 进行验证,从而让用户可以在没有服务器的情况下更新他们的数据。
目前来看,Web2 平台拥有自己的用户界面和后端,用于存储和控制用户数据。谷歌和 Facebook 利用这些数据,借助算法来差异化我们的用户体验,从而进一步收集数据。新的应用程序必须从头开始吸纳用户,不能从一开始就提供个性化的体验,因而也有着更低的市场竞争力。
Web3 实现了数据的民主化,为新产品和服务提供了公平的竞争环境,并为应用程序的实验和市场竞争创造了开放的平台。在一个用户可以把数据从一个平台带到另一个平台的世界里,应用开发者不需要从头开始便可以给用户带来个性化的体验。用户可以用他们的钱包进行登录,并授权应用程序读取/写入完全由他们自己控制的「数据库」。
Ceramic 上的 ComposeDB 是一个去中心化的图表数据库,应用开发者可以用 GraphQL 发现、创建、再利用可组合的数据模型。图表中的节点是账户(DID)或文件(数据流),其边界则代表了节点之间的关系。
DID 代表了可以向图表中写入数据的任何实体,例如终端用户(组)、应用程序或任何认证服务。
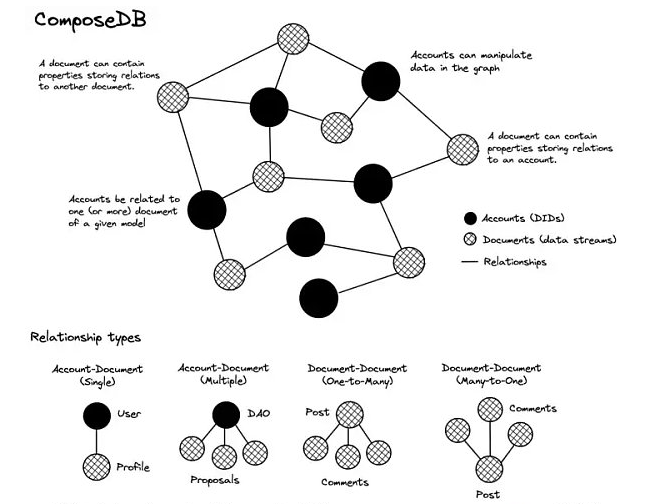
模型是存储有关文档数据结构、验证规则、关系和发现信息的元数据 Ceramic 流文件。开发人员可以创建、组合或混合模型,以形成可以作为其应用程序数据库的数据复合体。这将取代传统的用户表,其中包含中心化的 UID 和相关数据。应用程序可以构建在用户控制的公共数据集之上,而不用管理自己的独立表格。
由于应用程序在用于特定环境时可以无需权限地对模式进行定义,策展市场也因其可以为最有用的数据模型(为社交图谱、博客文章制定模式)提供信息而变得非常重要。在以这些数据模型运行的市场当中,应用程序可以为这些模型提供反馈,从而进一步优化它们。这激励了公共数据集生成更好的分析和图表,以便产品能在此基础上完成更多的创新。
Tableland 是用于可变、结构化关系数据的基础设施,其中每个表格都是作为 EVM 兼容链上的一个 NFT 被铸造的。NFT 的所有者可以为其表格设置访问控制逻辑,允许第三方在有合理写入权限的情况下对数据库上执行更新。Tableland 运行着一个链外验证者网络,用于管理表格的创建和后续的数据变化。
链上和链外更新均由一个智能合约处理,该合约使用 baseURI 和 tokenURI 连接至 Tableland 网络。借助 Tableland,NFT 元数据可以经访问控制被修改、使用 SQL 进行查询、并且可以与 Tableland 上的其他图表进行组合。
就像 ERC-20 和 ERC-721 这样的智能合约标准为 dapp 提供了一个创建和转移 Token 的共享语言,数据模型标准也让不同的应用程序之间实现了资料、声誉、DAO 提议和社交图谱的相互理解。由于任何人都可以向公共登记处进行提交,这些数据可以被多个应用重复使用。
应用程序与数据层的分离可以让用户在不同平台之间转移自己的内容、社交图和声誉。应用程序可以在各自的环境中使用相同的数据库,这样用户就能跨平台获得一个可组合的声誉。



下一篇
Web3 身份栈
-

- Alameda Research
- 2023-01-02
- 17878
- 钱包 广义上讲,钱包由用于密钥管理、通信(持有者、发行者和验证者之间的数据交换)以及声明展示和验证的接口和底层基础设施组成。 我们需要区分 Crypto 钱

24小时热点










热点专题

 5292806
5292806 







