区块链是一种共享数据库?
-
区块链硬核解析:区块链是一种共享数据库?
引言
这几年,学术和产业界对区块链的理解和应用产生了大量误区,本人也在过去的文章中逐步澄清和重新定义。不过,总觉得意犹未尽,没有专门立题成章。最近由于正在设计分布式产业协作模型,每到区块链技术运用精妙之处,觉得需要有系列文章来逐一解释这些误解。希望通过本人的反复倡导,可以为区块链产业运用提供更多的方案和定义。
这次我们首先讨论“区块链是共享数据库”这个说法到底有没有问题。在百度百科这样描述区块链:“区块链是一个信息技术领域的术语。从本质上讲,它是一个共享数据库,存储于其中的数据或信息,具有“不可伪造”“全程留痕”“可以追溯”“公开透明”“集体维护”等特征。”可以说大部分认为区块链是一种共享数据库的说法,受百度百科影响比较大。
接下来,我们就分析一下什么是共享数据库?

一、什么是共享数据库
本人通过“知网”搜索“共享数据库”关键字,并未发现直接匹配的论文,更多是关于数据共享模式的相关论文;通过百度百科词条搜索也没有发现“共享数据库”的概念描述,倒是有“共享存储”(概念完全不一样,感兴趣可以自行搜索)。可以说,一直以来“共享数据库”就不是学术和系统软件实践的概念,“共享数据库”更多的是互联网造词的畸形产物之一。
这是因为,无论从数据集成和共享模式分析,还是从数据库分类分析看,“共享数据库”都是一种伪命题。
首先,从数据库的定义上看:“数据库是按照数据结构来组织、存储和管理数据的仓库,是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合”[1],也就是说数据可共享本身就是数据库的基础功能之一,不需要额外使用区块链技术来建立数据库的数据共享能力。
其次,从数据库分类看,目前常见分类按照数据结构的组织不同,可分为:“关系型数据库”和“NoSQL数据库”;按照部署模式不同,可分为:“单机数据库”和“分布式数据库”等,也从未出现过按照数据共享程度分类的数据库。
再者,从数据共享方式上看,业界常采用数据集成,实现把不同来源、格式、特点性质的数据在逻辑上或物理上有机地集中,从而为企业提供全面的数据共享。通常采用联邦式、基于中间件模型和数据仓库等方法来构造数据集成的系统,并且已有很多成熟的框架可以利用。
所以,无论是数据库技术,还是企业数据共享模式的发展都从未出现过“共享数据库”这个概念,因为开发数据库软件的初衷本质上就是解决数据的组织、存储、管理和共享的。
二、为什么会认为区块链是共享数据库
上面讲到“区块链是一种共享数据库吗?”是一种伪命题,因为数据库的使命之一就是提升数据的访问和共享便捷性。那我们为什么有这样的定义呢?我猜测,“区块链是一种共享数据库”主要还是受一些通用底层区块链平台或产品的影响。
首先,大部分的公链平台,例如:Bitccoin、Ethereum、EOS等,本身并不是一个通用底层区块链平台,他们都是以点对点资产交易为核心构建区块链相关技术的组合应用,包括:加密技术、分布式技术、P2P数据传输、共识算法、链式数据结构、博弈论等。技术的运用是为点对点、安全、高效的资产交易达成服务的。所以在非资产处理的行业领域,例如:政务、工业、供应链等,直接使用基于公链的区块链技术往往会格格不入。由于公链平台业务目的是明确的,所以大家不会去讨论BitCoin是否是一个共享数据库的问题。
其次,在大部分已开展联盟链应用的行业中,底层大量采用Apache Hyperledger系列平台,受Hyperledger的影响颇深。以Hyperledger核心的Fabric为例,Fabric是一个业务目的不明确的通用区块链平台。从下图可以看到Fabric的节点主要由智能合约(早期的Chaincode)和分布式账本构成。而节点中的数据主要由分布式账本Ledger存储。
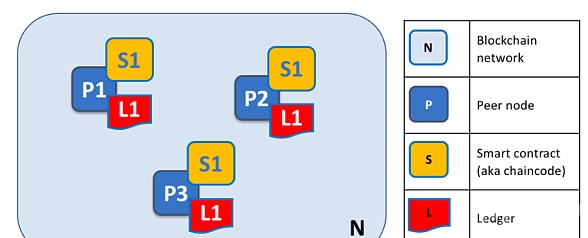
Fabric 节点构成 来源:Hyperledger Fabric技术白皮书[2]
而分布式账本Ledger又主要由Blockchain和全局状态构成,全局状态的更新被区块中的交易Transactions触发和决定。见下图:

Fabric 账本构成 来源:Hyperledger Fabric技术白皮书[2]
由下图可见,分布式账本Ledger中的全局状态World State本质确实是一种分布式的KV存储模型,再配合分布式节点网络,就不难解释为什么会认为区块链是一种共享数据库了。

Fabric 状态模型 来源:Hyperledger Fabric技术白皮书[2]
上面已经提到,Fabric是一种业务目的不明确的通用区块链平台,在Fabric的账本模型Ledger中,其实和我们日常理解的金融账本并没有直接关系,Ledger只是一种通用KV存储模型,你可以存储任意数据。在Fabric实际使用过程中,如果没有领域模型驱动,Fabric就真是一个分布式数据存储架构。
受这个因素影响,实际上我们在区块链行业应用中,大量采用Fabric的全局状态存储World State,实现分布式存储链。我在其他文章已经反复强调了,如果把区块链定位为分布式的数据存储机制,那和目前常用的分布式数据库相比没有任何技术优势,只是实现更复杂,效率更低而已。
三、数据的共享与数据存储结构无关
通过上面的分析,也确实可以把以Fabric为代表的区块链通用平台,定义为分布式数据存储模型,但这种分布式存储机制可以带来数据共享和开放吗?这里有个误区,是我们片面的理解为,数据分布式可带来数据的共享,但本文想强调,数据是否共享与存储结构和部署模式无关。
数据的存储结构和部署模式是物理模型,而数据的共享是业务模型。在当下“数据即资产”以及个人隐私保护和商业数据安全得到民众和舆论强化理解的当下,决定数据是否共享的关键,不是数据如何存储和部署,而是数据共享的业务必要性和多方参与者的利益是否得到平衡和保障。简单利用分布式存储机制解决“信息孤岛”问题,显然是异想天开了。
而且,大部分“信息孤岛”的问题,恰恰是数据分散存储和管理造成的,可以说数据的分布式是现状,而不是前景。解决数据分散造成的“信息孤岛”问题,首先要区分数据主权关系。在单一数据主权(绝对数据主权)下最高效的方法是数据集成,通过数据联邦、数据中间件和数据仓库等方式实现数据的汇聚;在多方数据主权(相对数据主权)关系下,则是通过法律强制或商业模式驱动,在合法合规的前提下让数据在数据应用相关方之间安全流动。
在无法建立数据集成的环境下,例如:多方数据主权、集成成本和法律限制条件,确实可以采用区块链技术建立数据可交易、可流动、可监管的可信数据共享网络。但这时区块链技术应用重点恰恰不是分布式的数据存储,而是数据资产的交易。如果没有建立数据资产交易模型,简单利用Fabric的全局状态,是无法实现数据共享的。
其实,以Bitcoin为代表的经典区块链技术,已经证明了区块链分布式节点中的数据存储只是为了保障各节点,可以本地化、高效的验证交易数据的真伪,而不是为数据共享为最终目的。
四、新技术驱动总是先带来哑铃效应
进入互联网Web2.0时代以来,大量新技术、新概念、新名词涌入产业界,从大数据、AI、5G、区块链再到今年的量子计算,每一次的新技术和产业结合都避免不了在国内产业圈出现技术认知的“哑铃效应”,即:哑铃的一头是高度概念化、抽象化,而另一头是高度的实例化和工具化。
区块链技术的兴起也是如此,一边是从概念化和抽象化上刻画区块链是一种去中心化,用网络自治代替中心化系统的价值互联网;而另一边则是将区块链描述为共享数据库,一种分布式存储工具。为什么会产生这样的认知呢?我想很大原因是,一种新技术的突然兴起,往往只是被几篇论文、几个应用场景点燃,但在广泛领域的应用型配套研究还未完全跟上,采用高度概念化、抽象化或实例化、工具化的定义,总能在现实世界找到映射关系,这是一种低成本的解释路径。
可以说,新技术发展的哑铃效应是一个必然过程,但随着新技术在领域实践中的知识积累和模型沉淀,将会不断修正哑铃的两端,让价值认知更为平滑、实用。爱因斯坦说过:“你无法在制造问题的同一思维层次上解决这个问题”,看待新技术往往不能直接从现实事物中直接匹配和映射,而是需要以创新思维在应用领域发展和完善新技术的定义和价值。
总结:
区块链技术在某种程度上确实可以充当分布式数据库或数据共享机制使用,但在实际应用中与传统数据集成框架相比,并无优势。同时由于采用分布式共识算法、P2P网络传输和区块数据结构等技术,系统复杂度更高、性能和可维护性更差。这么大的代价只是为了建立分布式一致性的存储机制显然是得不偿失的,也没有实际商业前途。利用区块链技术需要关注分布式的对等、安全、公平的交易环境的搭建上,以优化数据交易环境为前提,间接实现数据充分共享和利用。可以说在数据共享领域,区块链技术只是基础条件之一,而不是绝对因素。在数据所有权分散的环境下,决定数据是否可以共享,最重要的是业务和商业模型的确立。
参考文献:
[1]百度百科
https://baike.baidu.com/item/数据库/103728
[2]Apache hyperledger-fabric-readthedocs-io-en-release-2.0.pdf
- 区块链


下一篇
谈欧元与美元在数字货币领域竞争格局
-

- B网(Bittrex)交易所
- 2020-11-24
- 24304
- 在区块链技术和加密数字货币出现之前,欧元同美元之争已经存在
24小时热点
热点专题

 4278271
4278271