AIGC热门技术
-
AIGC热门技术
AIGC技术中,耳熟能详的当属GPT和Stable Diffusion了,作为一个技术er,应当了解一下其中的核心技术:Transformer、GPT、Diffusion、CLIP、Stable Diffusion
3.2.1 Transformer
Transformer主要用在语言模型(LM)上,Transformer是一个完全依赖于自注意力机制(Self-Attention)来计算其输入和输出的表示的转换模型,可以并行同时处理所有的输入数据,模仿人类联系上下文的习惯,从而更好地为大语言模型(LLM)注入意义并支持处理更大的数据集。
自注意力机制(Self-Attention):例:翻译The animal didn't cross the street because it was too tired. 以前的模型在处理该句子时,无法像人类一样判断it代指animal还是street,而Self-Attention机制的引入使得模型不仅能够关注当前位置的词,还能够关注句子中其他位置的词,从而在翻译时关联it和animal,提高翻译质量
语言模型(LM)是指对语句概率分布的建模。具体是判断语句的语序是否正常,是否可以被人类理解。它根据句子中先前出现的单词,利用正确的语序预测句子中下一个单词,以达到正确的语义。例如,模型比较“我是人类”和“是人类我”出现的概率,前者是正确语序,后者是错误语序,因此前者出现的概率比后者高,则生成的语句为“我是人类”
大型语言模型(LLM)是基于海量数据集进行内容识别、总结、翻译、预测或生成文本等的语言模型。相比于一般的语言模型,LLM 识别和生成的精准度会随参数量的提升大幅提高。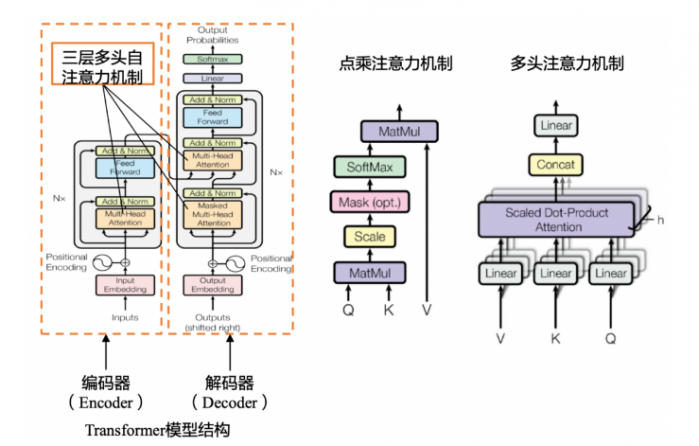
这里仅列出了Transformer整体模型。
3.2.2 GPT
当前最热门的大模型ChatGPT,其采用的大规模预训练模型GPT-3.5,核心便是transformer和RLHF两种语言模型。GPT的全称是Generative Pre-Trained Transformer,顾名思义,GPT的目的就是以Transformer为基础模型,使用预训练技术得到通用的文本模型。
预训练:指先通过一部分数据进行初步训练,再在这个训练好的基础模型上进行重复训练,或者说“微调”;
推理:指将预训练学习到的内容作为参考,对新的内容进行生成或判断。
预训练是模型运作的主要部分,所需要的精度较高,算力需求也较高;推理则相反。
人类反馈信号强化学习(RLHF):指使用强化学习的方式直接优化带有人类反馈的语言模型,使得语言模型能够与复杂的人类价值观“对齐”。它负责 ChatGPT 预训练中微调的部分,首先在人类的帮助下训练一个奖赏网络(RM),RM 对多个聊天回复的质量进行排序, 从而增加 ChatGPT 对话信息量,使其回答具有人类偏好。目前已经公布论文的有文本预训练GPT-1,GPT-2,GPT-3,以及图像预训练iGPT。GPT-4是一个多模态模型,具体细节没有公布。最近非常火的ChatGPT和今年年初公布的InstructGPT是一对姐妹模型,是在GPT-4之前发布的预热模型,有时候也被叫做GPT3.5。ChatGPT和InstructGPT在模型结构,训练方式上都完全一致,即都使用了指示学习(Instruction Learning)和人工反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)来指导模型的训练,它们不同的仅仅是采集数据的方式上有所差异。如下图所示,GPT-1,GPT-2,GPT-3三代模型都是采用的以Transformer为核心结构的模型,不同的是模型的层数和词向量长度等超参。
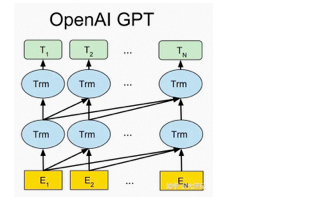
(其中Trm是一个Transformer结构)
下面将从GPT-1、GPT-2、GPT3、GPT3.5一直到GPT4,对GPT做一个简单介绍。


24小时热点
热点专题

 2324085
2324085 







