DM(Diffusion Model,扩散模型)
-
DM(Diffusion Model,扩散模型)
“扩散” 来自一个物理现象:当我们把墨汁滴入水中,墨汁会均匀散开;这个过程一般不能逆转,但是 AI 可以做到。当墨汁刚滴入水中时,我们能区分哪里是墨哪里是水,信息是非常集中的;当墨汁扩散开来,墨和水就难分彼此了,信息是分散的。类比于图片,这个墨汁扩散的过程就是图片逐渐变成噪点的过程:从信息集中的图片变成信息分散、没有信息的噪点图很简单,逆转这个过程就需要 AI 的加持了。

研究人员对图片加噪点,让图片逐渐变成纯噪点图;再让 AI 学习这个过程的逆过程,也就是如何从一张噪点图得到一张有信息的高清图。这个模型就是 AI 绘画中各种算法,如Disco Diffusion、Stable Diffusion中的常客扩散模型(Diffusion Model)。
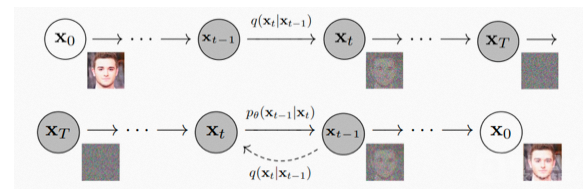
这里仅对Diffusion模型原理进行一个大致介绍,更加细节的推理不做赘述,有兴趣的同学可以自行学习。
3.2.4 CLIP( Contrastive Language-Image Pre-Training,大规模预训练图文表征模型)
大规模预训练图文表征模型用4亿对来自网络的图文数据集,将文本作为图像标签,进行训练。进行下游任务时,只需要提供和图上的concepts对应的文本描述,就可以进行zero-shot transfer。CLIP为CV研究者打开了一片非常非常广阔的天地,把自然语言级别的抽象概念带到计算机视觉里。
图片分类的zero-shot指的是对未知类别进行推理。
CLIP在进行zero-shot transfer时,将数据集中的类别标签转换为文字描述(100个类别就是100个文本描述)
zero-shot CLIP怎么做prediction?
zero-shot prediction:基于输入的图片,在类别描述中检索,找到最合适的类别。
Linear-probe evaluation:通过CLIP的image_encoder得到视觉向量,结合标签做Logistic Regression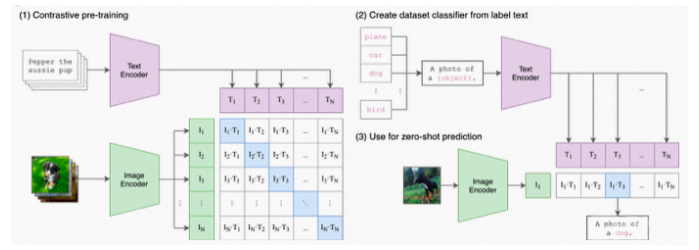
CLIP结构非常简单,将图片分类任务转换成图文匹配任务:
1、用两个encoder分别处理文本和图片数据,text encoder使用Transformer,image encoder用了2种模型,ResNet和Vision Transformer(ViT);
2、encoder representation直接线性投影到multi-modal embedding space;
3、计算两模态之间的cosine similarity,让N个匹配的图文对相似度最大,不匹配的图文对相似度最小;
4、对称的cross-entropy loss;
5、数据增强:对resized图片进行random square crop;
3.2.5 Stable Diffusion
当下AIGC的另一个大热点,AI绘画:只输入文字描述,即可自动生成各种图像。其核心算法-Stable Diffusion,就是上面提到的文字到图片的多模态算法CLIP和图像生成算法DIffusion的结合体。
参考论文中介绍算法核心逻辑的插图,Stable Diffusion的数据会在像素空间(Pixel Space)、潜在空间(Latent Space)、条件(Conditioning)三部分之间流转,其算法逻辑大概分这几步:
1、图像编码器将图像从像素空间(Pixel Space)压缩到更小维度的潜在空间(Latent Space),捕捉图像更本质的信息;
2、对潜在空间中的图片添加噪声,进行扩散过程(Diffusion Process);
3、通过CLIP文本编码器将输入的描述语转换为去噪过程的条件(Conditioning);
4、基于一些条件对图像进行去噪(Denoising)以获得生成图片的潜在表示,去噪步骤可以灵活地以文本、图像和其他形式为条件(以文本为条件即 text2img、以图像为条件即 img2img);
5、图像解码器通过将图像从潜在空间转换回像素空间来生成最终图像。
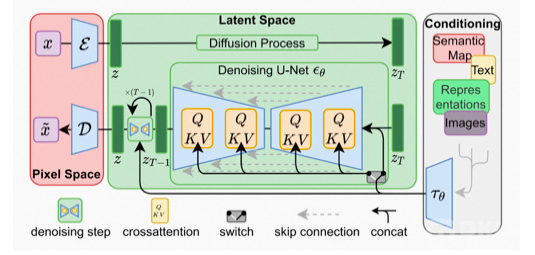
Diffusion和CLIP算法我们上面已经聊过了,潜在空间又是什么?
大家都有自己的身份证号码,前 6 位代表地区、中间 8 位代表生日、后 4 位代表个人其他信息。放到空间上如图所示,这个空间就是“人类潜在空间”。
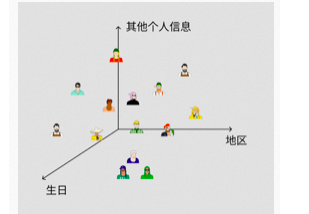
这个空间上相近的人,可能就是生日、地区接近的人。AI 就是通过学习找到了一个”图片潜在空间“,每张图片都可以对应到其中一个点,相近的两个点可能就是内容、风格相似的图片。同时这个 “潜在空间” 的维度远小于 “像素维度”,AI 处理起来会更加得心应手,在保持效果相同甚至更好的情况下,潜在扩散模型对算力、显卡性能的要求显著降低。
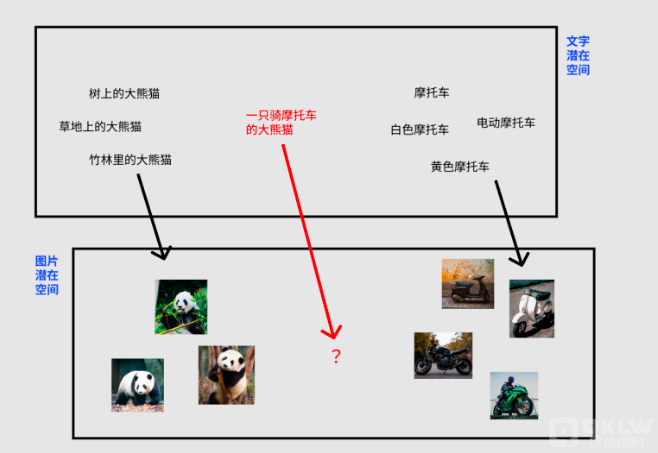
当 AI 建立了“文字潜在空间”到“图片潜在空间”的对应关系,就能够通过文字控制图片的去噪过程,实现通过文字描述左右图像的生成。

下一篇
大模型使得AIGC有了更多的可能
-

- 币信
- 2023-07-09
- 15364
- 大模型使得AIGC有了更多的可能 视觉大模型提高AIGC感知能力 以图像和视频为代表的视觉数据是我们这个时代下信息的主要载体之一,这些视觉信息
24小时热点
热点专题

 2324085
2324085 







