
Data50公司涵盖类型有7个子类别
-
50家世界顶级数据初创公司一览
在“大数据”概念诞生十多年后,数据仍然是大型企业和初创企业中最重要、增长最迅猛的创新驱动因素之一。从提供作为商业运作基础的脉搏检查,到通过机器学习实现日常任务的智能自动化,数据已经成为各种规模组织决策的中枢神经系统。此外,数据的使用已经远远超出了数据科学家、数据分析师和数据工程师的范畴—每个人都是数据生产者和消费者。
这种对数据更加关注的结果是:数据管理业务已经成为基础设施增长最快的领域之一,据估计价值超过700亿美元,占2021年所有企业基础设施支出的五分之一以上。这个市场形成的原因在于,它结合了软件工程、分析和人工智能领域,同时顺应了云计算的潮流势头。(有关这一巨大趋势背后的架构演变和驱动力的更多信息,可以参阅《现代数据基础设施的新兴架构》。)
过去几年,数据行业的发展也催生了一些令人兴奋和有影响力的企业软件公司。最近,Snowflake和Confluent等公共巨头已经改变了数千家企业的运营方式和数百万种产品的生产方式。然而,大多数人都不太熟悉那些有影响力的公司,也就是下一代定义类别的公司。
2021年,数据公司获得了数百亿美元的风险投资,打破了历史记录,2022年的风险投资也已经很强劲。我们编制了Data50的首批数据。这些是令人兴奋的数据类别中的领头羊公司。总体而言,这50家公司的价值超过1000亿美元,并且筹集了大约145亿美元的总资本,其中20家到2021年已达到独角兽地位。
Data50公司涵盖类型有7个子类别:
AI/ML(人工智能/机器学习)、BI & Notebooks(商业智能和笔记本)、Customer Data Analytics(客户数据分析)、Data Governance & Security(数据治理与安全)、Data Observability(数据可观察性)、ELT & Orchestration(ELT 与编排)、Query and Processing(查询与处理)。

1、查询和处理技术是访问、聚合和计算数据的核心引擎。它涉及两大类:批处理(如Databricks和Starburst)和实时处理(如ClickHouse和Imply)。在过去的几年里,由于对实时应用程序的需求不断增加,后者得到了越来越多的关注。
2、AI/ML(人工智能和机器学习)包括应用算法建模和机器学习处理大规模数据的软件。从上榜公司的数量来看,这一领域正在成熟和繁荣。一些参与者专注于一个特定类型的数据(例如自然语言的Rasa和Hugging Face),而另一些则专注于不同的领域,例如AI的产品化(例如 Scale、Tecton和Weights and Biases)或充当用于运行AI工作负载(例如Anyscale)的“计算层”。
3、ELT和编排支持数据的移动。它是保证数据准确、准时到达目的地的传输层。此类别是从传统的ETL供应商演化而来的。另一方面,新类别的玩家大多是云原生的(例如Fivetran和dbt),对开发人员友好(例如Astronomer和Prefect),并且可以处理不同数据环境之间更复杂的依赖关系。
4、随着数据堆栈变得越来越复杂并且涉及更多利益相关者,数据治理和安全性正成为关键问题。需要治理工具—尤其是在高度规范的行业—来确保数据的安全并在整个数据生命周期中保持一致性(例如OneTrust和Collibra)。这一类别相对较新,通常服务于受监管的大型企业公司。
5、传统上,客户数据分析由营销团队负责。然而,由于其重要性日益增加,数据团队现在更多地参与将客户数据与中央数据平台集成。此类别侧重于捕获客户数据(例如Rudderstack和ActionIQ)或操作该数据以服务于一线业务用例(例如Census和Hightouch)。
6、BI & notebooks覆盖了数据的消费层。尽管它是一个成熟的类别,但Preset或Metabase等新参与者正在采取开源优先的方法,并吸引技术数据工程师以及商业智能团队。数据需求的快速变化性质也对迭代和交互式笔记本(例如Hex)和自动洞察生成(例如Sisu)产生了更多需求。
数据可观察性从软件工程堆栈的最佳实践中汲取灵感。随着数据堆栈越来越依赖于上下游工具,并且数据的准确性具有更广泛的影响,可观察性成为提供跨数据流监控和诊断能力的最新类别。
尽管市场采用的主要推动力是数据量和使用量的增加,但每个类别的潜在驱动力是不同的。例如,查询和处理领域的进步主要是由计算和存储的分离、迁移到云以及更廉价的计算能力驱动的。与此同时,在数据治理和数据可观察性中采用操作性工具在很大程度上是由不断增长的操作性用例和数据工作流的复杂性驱动的。
以下为Data50公司名单(名称、类型、地点、估值范围及网站情况):
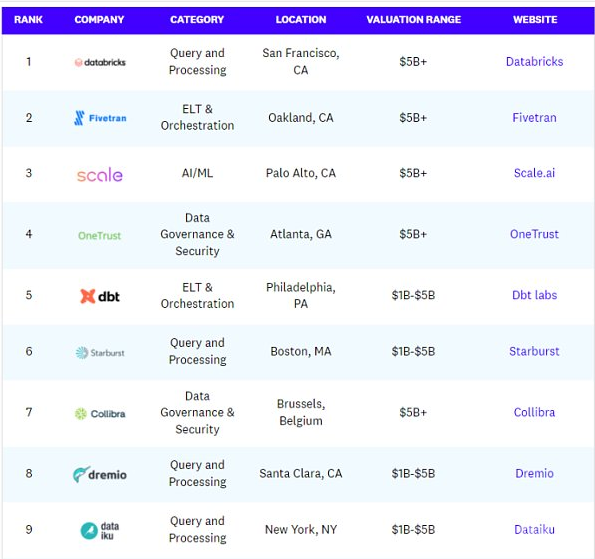
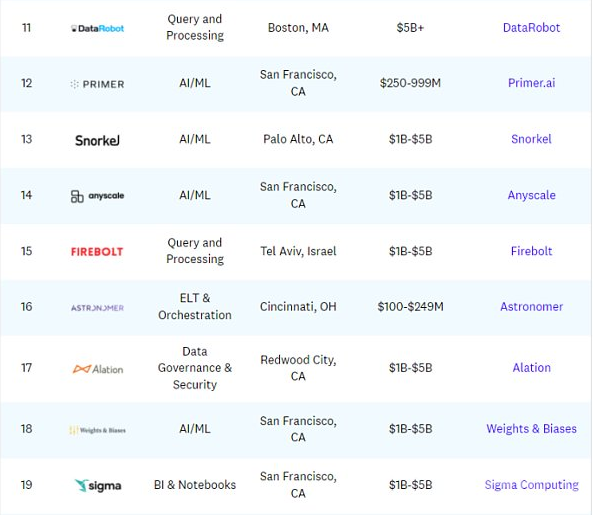
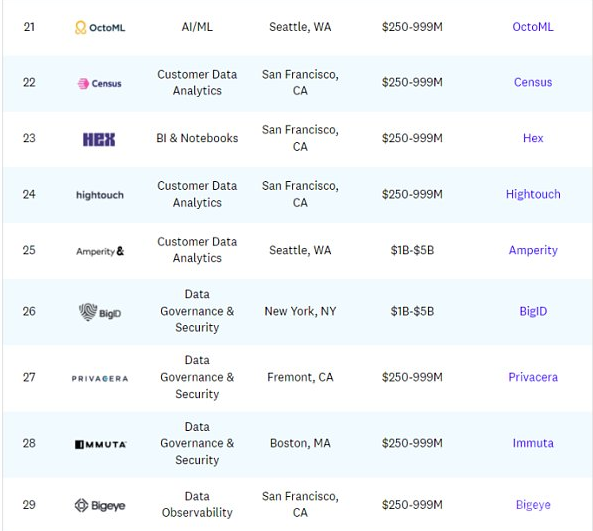
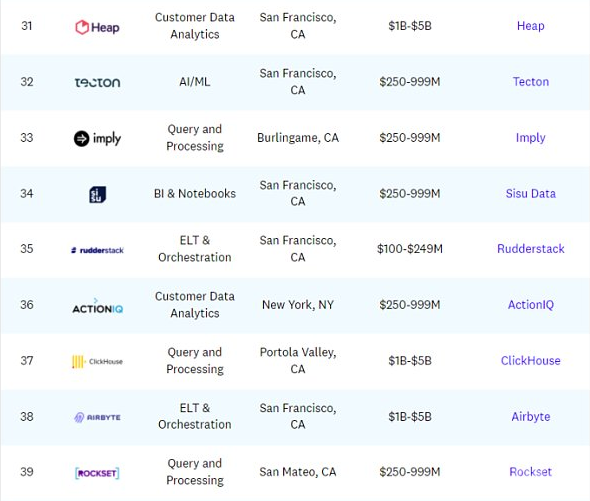
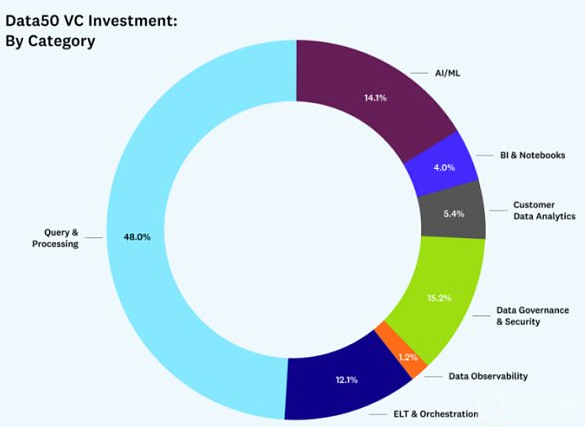
从细分角度(融资分布、数量分布、地点分布)看Data50:
查询和处理公司筹集了最大的资本份额
查询和处理类别只占Data50中公司的五分之一,但投资在这一类别的资金数额(几乎占所有资金的 50%)是惊人的。尽管这一数据受到了Databricks最近16亿美元融资的影响,但如果没有它,这一类别仍将占所有融资的37%,是下一个类别的两倍多。
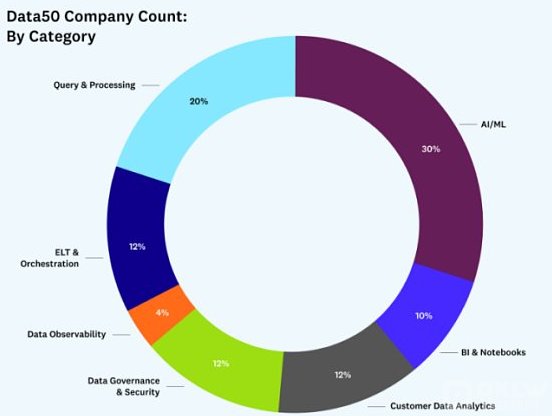
从公司数量来看,分布更为均衡。就公司数量而言,AI/ML 是最大的类别,主要是因为该领域仍在不断发展,需要一套新的独立工具来训练、测量和生产模型。(有关该领域如何发展的更多信息,请阅读现代数据基础设施的新兴架构。)
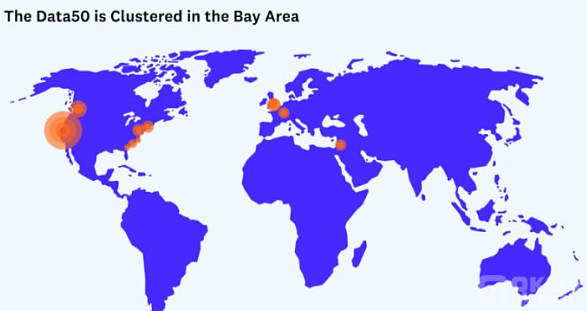
Data50集中在旧金山湾区
在这50家公司中,47家(94%)位于美国,3家是跨国公司。其中33家公司位于旧金山湾区,9家位于华盛顿特区、费城、纽约和波士顿的I-95走廊沿线。其中两家位于西雅图,一家位于辛辛那提,还有一家位于亚特兰大。
这种分布受到大规模数据生态系统历史位置的严重影响(例如,Oracle和Teradata都在湾区成立)。然而,我们看到越来越多的数据公司(如Firebolt和Matillion)出现在全球各地,因为数据工程人才和对数据工具的需求几乎遍及每个大陆。
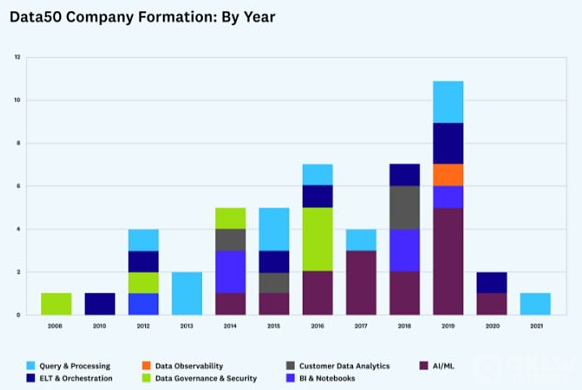
AI/ML 类别推动了 2019 年新数据公司的激增
大多数 Data50 公司成立于 2014 年之后,在 AI/ML 工具爆炸式增长的推动下,在2019 年左右达到顶峰。事实上,2019 年之后成立了更多的数据公司,但是因为我们关注的是已经达到一定规模的公司,所以大多数新公司还没有出现在这个名单上。
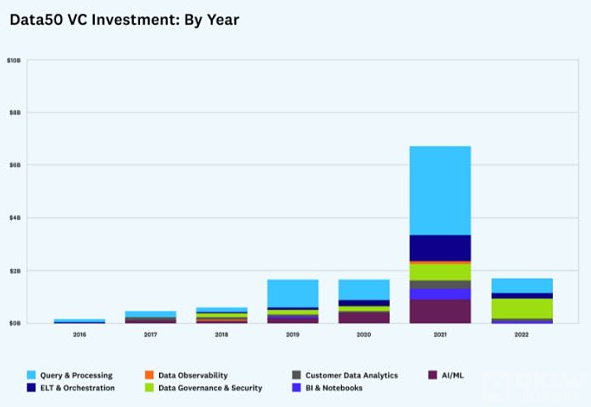
每个类别的投资都在增长
从每个类别的投资来看,最显着的趋势是 AI/ML 公司比以往任何时候都获得了更多的投资者兴趣,主要集中在早期阶段。 ELT 和编排也是如此——主要由来自 Fivetran 和 dbt 的巨轮驱动。 查询和处理公司继续吸引大笔资金,尽管这些公司往往处于后期阶段。
本文作者为Jennifer Li、Sarah Wang、Jamie Sullivan。Jennifer Li是 a16z 的合伙人,她专注于企业公司。Sarah Wang是 a16z 的普通合伙人,专注于成长阶段的投资。Jamie Sullivan是 a16z Growth 投资团队的合伙人,专注于消费者、企业和金融科技领域的后期公司。
在本文结尾,作者指出,我们坚信,未来10年将是数据的十年,包括基础设施、应用程序以及介于两者之间的一切。因此,我们将继续看到创纪录的增长、资金和市值,我们将在此列表中每年对其进行跟踪。





24小时热点










热点专题

 2318557
2318557 





