谷歌Gemini 1.5 Pro在基准测试中超越GPT-4o,成为新一代AI模型霸主
-
生成式人工智能领域迎来了新霸主——Gemini 1.5 Pro。在8月1日的最新基准测试中,谷歌的这款新模型超越了OpenAI的GPT-4o,成为了新的标杆。
谷歌Gemini的突围
尽管谷歌的Gemini 1.5 Pro在发布时并未大张旗鼓,但它迅速引起了人工智能社区的关注。该模型的实验版本被标记为“实验性”,但其卓越的基准测试成绩使其成为了讨论的焦点。
基准测试的变革
自GPT-3问世以来,OpenAI的ChatGPT一直在生成式AI领域占据主导地位。特别是GPT-4o与Anthropic的Claude-3,在大多数主流基准测试中均遥遥领先。最受欢迎的测试之一是LMSYS Chatbot Arena,该测试评估模型在各种任务中的能力。
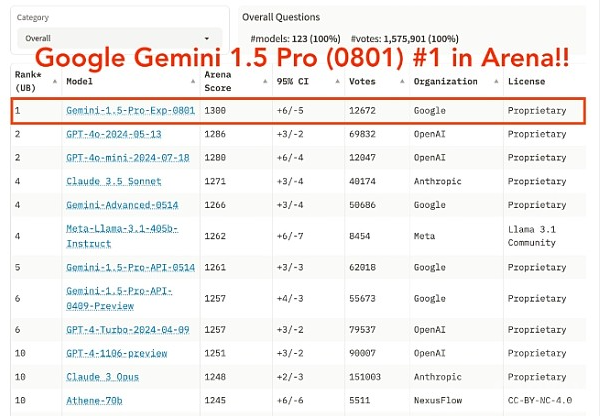
在最新的基准测试中,GPT-4o的得分为1,286,Claude-3则获得了1,271分。Gemini 1.5 Pro的前一个版本得分为1,261,而新发布的实验版本(Gemini 1.5 Pro 0801)则以1,300分打破了记录。这一成绩显示,Gemini 1.5 Pro在总体表现上超越了目前的竞争对手。
AI社区的兴奋
尽管基准测试提供了有价值的比较,但它并不总能全面反映AI模型的实际能力。随着市场上AI聊天机器人的逐渐成熟,用户最终将决定哪种模型最适合他们的需求。
Gemini 1.5 Pro的发布在社交媒体上引发了热烈讨论。许多用户对其表现赞不绝口,一位Reddit用户甚至表示,该模型“完全超越了4o”。
尽管Gemini 1.5 Pro的实验版本目前广泛可用,但由于其处于早期测试阶段,未来是否会成为默认版本尚未确定。谷歌可能会根据测试反馈进行调整或撤销该模型,以确保其安全性和稳定性。

下一篇
比特币的四年周期是否正在走向终结?
-

- 波场区块链浏览器
- 2024-08-02
- 10261
- 比特币的四年周期,一种由减半事件驱动的市场模式,一直以来都是投资者和加密货币爱好者关注的焦点。这一周期涉及比特币的供应减少、价格上涨及其后的市场调整。然而,随着市场动态和经济环境的不断变化,我们需要重新审视这一周期是否正逐步走向终结。本文将探讨比特币四年周期结束的可能性,并分析相关证据。
24小时热点
热点专题

 79010
79010