训练模型是什么意思
-

- 电子数据保全鉴证平台
- 2023-07-06
- 栏目:区新闻
- --
-
 APP下载
APP下载
-
一、前言
行业大佬都在投身大模型赛道,大模型有什么魅力?ChatGPT火热,是人类生产力的解放?
二、大模型
2.1 不是模型参数大就叫大模型
关于大模型,有学者称之为“大规模预训练模型”(large pretrained language model),也有学者进一步提出”基础模型”(Foundation Models)的概念
2021年8月,李飞飞、Percy Liang等百来位学者联名发布了文章:On the Opportunities and Risks of Foundation Models[1],提出“基础模型”(Foundation Models)的概念:基于自监督学习的模型在学习过程中会体现出来各个不同方面的能力,这些能力为下游的应用提供了动力和理论基础,称这些大模型为“基础模型”。
“小模型”:针对特定应用场景需求进行训练,能完成特定任务,但是换到另外一个应用场景中可能并不适用,需要重新训练(我们现在用的大多数模型都是这样)。这些模型训练基本是“手工作坊式”,并且模型训练需要大规模的标注数据,如果某些应用场景的数据量少,训练出的模型精度就会不理想。
“大模型”:在大规模无标注数据上进行训练,学习出一种特征和规则。基于大模型进行应用开发时,将大模型进行微调(在下游小规模有标注数据进行二次训练)或者不进行微调,就可以完成多个应用场景的任务,实现通用的智能能力。
2.2 大模型赛道早已开始
多语言预训练大模型
- Facebook已发布了一个百种语言互译的模型M2M-100,该模型不依赖英文作为中介语言,可实现一百种语言之间的直接翻译,在机器翻译领域实现新突破。
- 谷歌宣布开源了多语言模型MT5,基于101种语言进行训练,采用750GB文本,最大含有130亿个参数, 目前已在大多数多语言自然语言处理任务基准测试中达到最优水平,包括机器翻译、阅读理解等。
多模态预训练大模型
OpenAI已研发DALL·E、CLIP等多模态模型,参数达120亿,在图像生成等任务上取得优秀表现。
多任务预训练大模型
谷歌在2022年的IO大会上公开了MUM(多任务统一模型 : Multitask Unified Model)的发展情况。据谷歌透露,MUM模型基于大量的网页数据进行预 训练,擅长理解和解答复杂的决策问题,能够理解75种语言,从跨语言多模态网页数据中寻找信息。
视觉预训练大模型
具备视觉通用能力的大模型,如ViTransformer等。视觉任务在日常生活和产业发展中占据很大的比重,视觉大模型有可能在自动驾驶等依赖视觉处理的领域加速应用。
2.3 深度学习范式即将改变
AI的研发和应用范式可能会发生极大的变化,各位大佬或许也是因为看到了深度学习2.0时代的到来,纷纷投身大模型赛道。
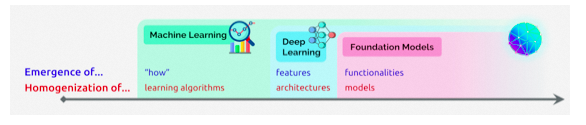
上图源自李飞飞、Percy Liang等百来位学者联名发布的文章[1]
machine learning homogenizes learning algorithms (e.g., logistic regression), deep learning homogenizes model architectures (e.g., Convolutional Neural Networks), and foundation models homogenizes the model itself (e.g., GPT-3)
如文中所说,机器学习同质化学习算法(例如逻辑回归)、深度学习同质化模型结构(例如CNN),基础模型则同质化模型本身(例如GPT-3)。
人工智能的发展已经从“大炼模型”逐步迈向了“炼大模型”的阶段。ChatGPT只是一个起点,其背后的Foundation Module的长期价值更值得被期待。
2.4 大模型不是一跃而起的
大模型发展的前期被称为预训练模型,预训练技术的主要思想是迁移学习。当目标场景的数据不足时,首先在数据量庞大的公开数据集上训练模型,然后将其迁移到目标场景中,通过目标场景中的小数据集进行微调 ,使模型达到需要的性能 。在这一过程中,这种在公开数据集训练过的深层网络模型,被称为“预训练模型”。使用预训练模型很大程度上降低下游任务模型对标注数据数量的要求,从而可以很好地处理一些难以获得大量标注数据的新场景。
2018年出现的大规模自监督(self-supervised)神经网络是真正具有革命性的。这类模型的精髓是从自然语言句子中创造出一些预测任务来,比如预测下一个词或者预测被掩码(遮挡)词或短语。这时,大量高质量文本语料就意味着自动获得了海量的标注数据。让模型从自己的预测错误中学习10亿+次之后,它就慢慢积累很多语言和世界知识,这让模型在问答或者文本分类等更有意义的任务中也取得好的效果。没错,说的就是BERT 和GPT-3之类的大规模预训练语言模型,也就是我们说的大模型。
2.5 为什么大模型有革命性意义?
突破现有模型结构的精度局限
2020年1月,OpenAI发表论文[3],探讨模型效果和模型规模之间的关系。
结论是:模型的表现与模型的规模之间服从Power Law,即随着模型规模指数级上升,模型性能实现线性增长
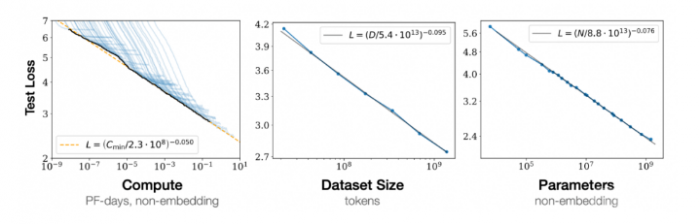
2022年8月,Google发表论文[4],重新探讨了模型效果与模型规模之间的关系。
结论是:当模型规模达到某个阈值时,模型对某些问题的处理性能呈现快速增长。作者将这种现象称为Emergent Abilities,即涌现能力。
预训练大模型+细分场景微调更适合长尾落地
用著名NLP学者斯坦福大学的Chris Manning教授[2]的话来说,在未标注的海量语料上训练大模型可以:
Produce one large pretrained model that can be very easily adapted, via fine-tuning or prompting, to give strong results on all sorts of natural language understanding and generation tasks.
通过微调或提示,大规模预训练模型可以轻松地适应各种自然语言理解和生成任务,并给出非常强大的结果。Transformer 架构自2018年开始统治NLP领域,NLP领域的进展迎来了井喷。为何预训练的transformer有如此威力?其中最重要的思想是attention,也就是注意力机制。Attention其实非常简单,就是句子中每个位置的表征(representation,一般是一个稠密向量)是通过其他位置的表征加权求和而得到。Transformer模型通过每个位置的query, key以及value的表征计算来预测被掩码位置的单词,大致过程如下图所示,更具体的细节这里不再赘述。

2.6 为什么这么简单的结构和任务能取得如此威力?
原因在其通用性。
预测下一个单词这类任务简单且通用,以至于几乎所有形式的语言学和世界知识,从句子结构、词义引申、基本事实都能帮助这个任务取得更好的效果。大模型也在训练过程中学到了这些信息,让单个模型在接收少量的指令后就能解决各种不同的NLP问题。也许,大模型就是“大道至简”的最好诠释。
基于大模型完成多种NLP任务,在2018年之前靠fine-tuning(微调),也就是在少量针对任务构建的有监督数据上继续训练模型。后来则出现了prompt(提示学习)这种形式,只需要对任务用语言描述或者给几个例子,模型就能很好的执行以前从未训练过的任务。
大模型还改变了NLP的范式
传统的NLP是流水线范式:先做词法(如分词、命名实体识别)处理,再做句法处理(如自动句法分析等),然后再用这些特征进行领域任务(如智能问答、情感分析)。这个范式下,每个模块都是由不同模型完成的,并需要在不同标注数据集上训练。而大模型出现后,就完全代替了流水线模式,比如:
- 机器翻译:用一个模型同时搞多语言对之间的翻译
- 智能问答:基于LPLM(large pretrained language model)微调的模型效果明显提升
- 其他NLU(natural language understanding)任务如NER(Named entity recognition)、情感分析也是类似
更值得一提的是 NLG (natural language generation),大模型在生成通顺文本上取得了革命性突破,对于这一点玩过ChatGPT的同学一定深有体会。
大模型能在NLP任务上取得优异效果是毋庸置疑的,但我们仍然有理由怀疑大模型真的理解语言吗,还是说它们仅仅是鹦鹉学舌?
2.7 大模型能真正理解人类语言吗?
要讨论这个问题,涉及到什么是语义,以及语言理解的本质是什么。关于语义,语言学和计算机科学领域的主流理论是指称语义(denotational semantics),是说一个单词短语或句子的语义就是它所指代的客观世界的对象。与之形成鲜明对比的是,深度学习NLP遵循的分布式语义(distributional semantics),也就是单词的语义可以由其出现的语境所决定。
Meaning arises from understanding the network of connections between a linguistic form and other things, whether they be objects in the world or other linguistic forms.
意义来源于理解语言形式与其他事物之间的连接,无论它们是语言形式还是世界上其他的物体。引用NLP大佬Manning的原话,用对语言形式之间的连接来衡量语义的话,现在的大模型对语言的理解已经做的很好了。但局限性在于,这种理解仍然缺乏世界知识,也需要用其他模态的感知来增强,毕竟用语言对图像和声音等的描述,远不如这些信号本身来的直接。(没错,GPT-4!)
三、AIGC(AI Generated Content)
在大模型的加持下,AIGC有望帮助内容生成跨越新时代。
3.1 简单认识AIGC
- 什么是AIGC?
目前,对AIGC这一概念的界定,尚无统一规范的定义。国内产学研各界对于AIGC的理解是“继专业生成内容(Professional Generated Content,PGC)和用户生成内容(User Generated Content,UGC)之后,利用人工智能技术自动生成内容的新型生产方式”。
- AIGC能做什么?
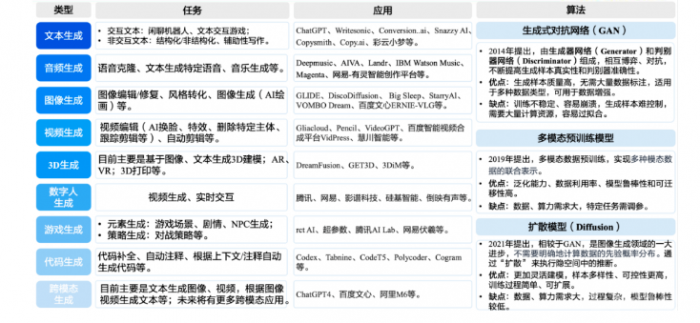
- AIGC的发展历程
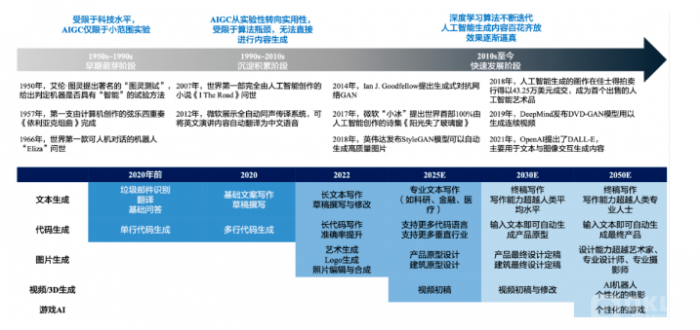
3.2 AIGC热门技术
AIGC技术中,耳熟能详的当属GPT和Stable Diffusion了,作为一个技术er,应当了解一下其中的核心技术:Transformer、GPT、Diffusion、CLIP、Stable Diffusion
3.2.1 Transformer
Transformer主要用在语言模型(LM)上,Transformer是一个完全依赖于自注意力机制(Self-Attention)来计算其输入和输出的表示的转换模型,可以并行同时处理所有的输入数据,模仿人类联系上下文的习惯,从而更好地为大语言模型(LLM)注入意义并支持处理更大的数据集。
自注意力机制(Self-Attention):例:翻译The animal didn't cross the street because it was too tired. 以前的模型在处理该句子时,无法像人类一样判断it代指animal还是street,而Self-Attention机制的引入使得模型不仅能够关注当前位置的词,还能够关注句子中其他位置的词,从而在翻译时关联it和animal,提高翻译质量
语言模型(LM)是指对语句概率分布的建模。具体是判断语句的语序是否正常,是否可以被人类理解。它根据句子中先前出现的单词,利用正确的语序预测句子中下一个单词,以达到正确的语义。例如,模型比较“我是人类”和“是人类我”出现的概率,前者是正确语序,后者是错误语序,因此前者出现的概率比后者高,则生成的语句为“我是人类”
大型语言模型(LLM)是基于海量数据集进行内容识别、总结、翻译、预测或生成文本等的语言模型。相比于一般的语言模型,LLM 识别和生成的精准度会随参数量的提升大幅提高。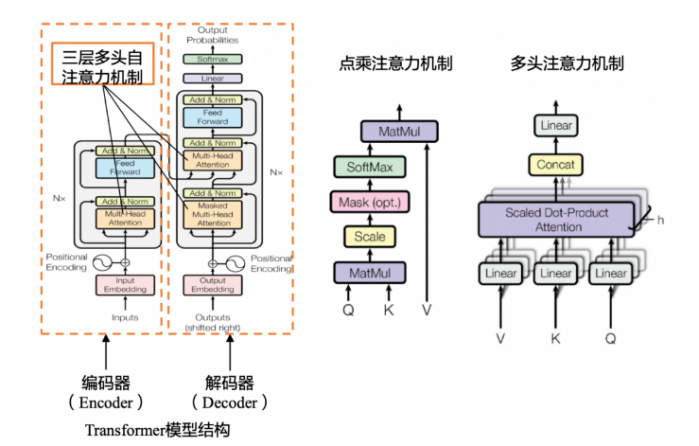
这里仅列出了Transformer整体模型。
3.2.2 GPT
当前最热门的大模型ChatGPT,其采用的大规模预训练模型GPT-3.5,核心便是transformer和RLHF两种语言模型。GPT的全称是Generative Pre-Trained Transformer,顾名思义,GPT的目的就是以Transformer为基础模型,使用预训练技术得到通用的文本模型。
预训练:指先通过一部分数据进行初步训练,再在这个训练好的基础模型上进行重复训练,或者说“微调”;
推理:指将预训练学习到的内容作为参考,对新的内容进行生成或判断。
预训练是模型运作的主要部分,所需要的精度较高,算力需求也较高;推理则相反。
人类反馈信号强化学习(RLHF):指使用强化学习的方式直接优化带有人类反馈的语言模型,使得语言模型能够与复杂的人类价值观“对齐”。它负责 ChatGPT 预训练中微调的部分,首先在人类的帮助下训练一个奖赏网络(RM),RM 对多个聊天回复的质量进行排序, 从而增加 ChatGPT 对话信息量,使其回答具有人类偏好。目前已经公布论文的有文本预训练GPT-1,GPT-2,GPT-3,以及图像预训练iGPT。GPT-4是一个多模态模型,具体细节没有公布。最近非常火的ChatGPT和今年年初公布的InstructGPT是一对姐妹模型,是在GPT-4之前发布的预热模型,有时候也被叫做GPT3.5。ChatGPT和InstructGPT在模型结构,训练方式上都完全一致,即都使用了指示学习(Instruction Learning)和人工反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)来指导模型的训练,它们不同的仅仅是采集数据的方式上有所差异。如下图所示,GPT-1,GPT-2,GPT-3三代模型都是采用的以Transformer为核心结构的模型,不同的是模型的层数和词向量长度等超参。
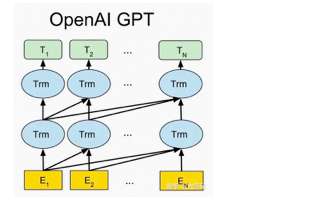
(其中Trm是一个Transformer结构)
下面将从GPT-1、GPT-2、GPT3、GPT3.5一直到GPT4,对GPT做一个简单介绍。
- GPT-1
主要解决的问题:怎么在无标号数据上面预训练大模型?
GPT使用语言模型来进行预训练,并使用了n-gram方法对当前单词进行预测。通俗的说,也就是根据前k个单词来预测下一个单词谁什么,大量高质量文本语料就意味着自动获得了海量的标注数据。最关键的是如何优化目标函数,因为不同的任务目标函数设定是不一样的。GPT使用对数最大似然函数来计算loss,使用transformer的解码器(因为有掩码不能看到完整的句子信息),并且其中使用了position embedding引入了位置信息。
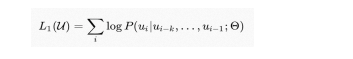
怎么做模型微调?
微调时使用的是带有标号的数据集,每次输入长度为m的一条序列x,这条序列有一个标号y。模型根据输入的序列x预测其标号y(标准分类任务)。要考虑的是如何将nlp下游的子任务表示成我们想要的形式,即一些序列和其相应的标号。
怎么根据任务的不同改变下游输入?
如下图所示,其中start(起始)、delim(分割)和 extract(终止)是特殊字符,文本中不会出现的字符。
- 分类任务(classification):输出是分类类别。
- 蕴含任务(entailment):输出是是与否,是否蕴含这个关系。
- 相似性任务:相似是一个对称关系,但是语言模型是有顺序的,所以做了两种拼接,最后输出是二分类,相似或不相似。
- 多选题:问一个问题给出几个答案选出认为正确的问题,输出的是每个答案对于这个问题是正确答案的置信度。
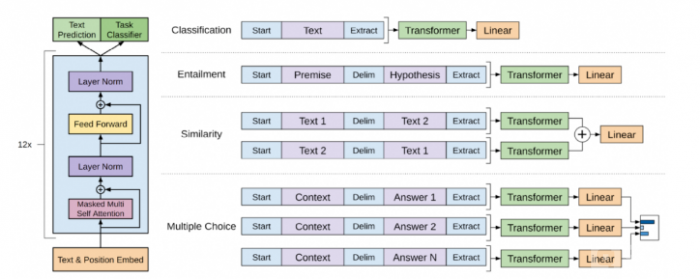
- GPT-2
主要解决的问题:当模型被别人用更大的数据集参数量打败时,应该怎么做?
GPT2虽然还是在做语言模型,但是下游任务使用了一个叫做zero-shot的设定,即做下游任务时不需要下游任务的任何标注信息,也不需要训练模型——只要预训练一个大模型来预测子任务,这个预训练的大模型在任何地方都可以用。
GPT1和GPT2的区别
在GPT1时我们在构建下游任务输入时引入了起始、截断和终止符,这些模型在开始的预训练阶段时没有看到的,但是有微调的情况时,模型可以再学习到这些符号的意思。但是GPT2要做zero-shot时,在做下游任务时模型不能被调整了,再引入这些特殊字符时模型会感到很困惑,所以在构建下游任务输入时不能引入那些模型没见过的符号,而需要使下游任务的输入和之前预训练时模型看到的文本长得一样,输入形式应该更像一个自然语言。
例如:在做句子翻译任务时,训练的句子可以被写为:(translate to french, english text, french text).
其中translate to french在后文叫做prompt也叫做提示,相当于做了一个特殊的提示词。
如果要做阅读理解任务时:可以写作(answer the question, document(阅读的文本), question, answer)
answer the question相当于任务提示。
这些构建提示词的方式是前人提出的,假设为如果训练的模型足够强大就可以理解这些提示词的意思,而且这种提示词在文本中也比较常见,模型可以理解。GPT2的数据集
没有选择Common Crawl这种具有很多冗余无用信息的项目,选用的是reddit里面已经被人工筛选出的有意义的,并且具有至少3karma值的网页进行数据处理,大概有800万个文本,40gb的文字。
- GPT-3
主要解决的问题:
1.做下游子任务时需要大量有标号的数据集。
2.样本没有出现在数据分布里面,大模型的泛化性不见得比小模型更好。微调效果好不能说明预训练模型泛化性好,因为可能是过拟合预训练的训练数据,这些训练数据与微调使用的数据刚好有一定的重合性。
3.人类不需要一个很大的数据集做任务。
为了解决上面几个问题,GPT-3的训练使用了情境学习(In-context Learning),它是元学习(Meta-learning)的一种,元学习的核心思想在于通过少量的数据寻找一个合适的初始化范围,使得模型能够在有限的数据集上快速拟合,并获得不错的效果。
GPT3的数据集
使用了之前GPT2中弃用的Common Crawl的数据,构建数据步骤:
1、使用之前的reddit的数据作为正例,Common Crawl作为负例训练二分类器,预测Common Crawl的网页,过滤掉不好的
2、使用lsh算法(常用技术)去重
3、增加已知高质量数据,把之前的BERT、GPT1、GPT2数据集拿过来
4、因为Common Crawl数据集还是很脏,所以在真实采样时赋予了一定权重进行采样:
- GPT3.5(ChatGPT/InstructGPT)
主要解决的问题:预训练模型具有偏见性。
预训练模型就像一个黑盒子,没有人能够保证预训练模型不会生成一些包含种族歧视,性别歧视等危险内容,因为它的几十GB甚至几十TB的训练数据里几乎肯定包含类似的训练样本。InstructGPT/ChatGPT都是采用了GPT-3的网络结构,通过指示学习构建训练样本来训练一个反应预测内容效果的奖励模型(RM),最后通过这个奖励模型的打分来指导强化学习模型的训练。
什么是指示学习?
指示学习是谷歌Deepmind的Quoc V.Le团队在2021年的一篇名为《Finetuned Language Models Are Zero-Shot Learners》文章中提出的思想。指示学习(Instruct)和提示学习(Prompt)的目的都是去挖掘语言模型本身具备的知识。不同的是Prompt是激发语言模型的补全能力,例如根据上半句生成下半句,或是完形填空等。Instruct是激发语言模型的理解能力,它通过给出更明显的指令,让模型去做出正确的行动。指示学习的优点是它经过多任务的微调后,也能够在其他任务上做zero-shot,而提示学习都是针对一个任务的。泛化能力不如指示学习。
我们可以通过下面的例子来理解这两个不同的学习方式:
1.提示学习:给女朋友买了这个项链,她很喜欢,这个项链太____了。
2.指示学习:判断这句话的情感:给女朋友买了这个项链,她很喜欢。选项:A=好;B=一般;C=差。怎么消除偏见的?
人工反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF),将人工反馈作为强化学习的奖励,将模型的输出内容和人类喜欢的输出内容的对齐。人类喜欢的不止包括生成内容的流畅性和语法的正确性,还包括生成内容的有用性、真实性和无害性。
ChatGPT和InstructGPT的训练方式相同,不同点仅仅是它们采集数据上有所不同,但是并没有更多的资料来讲数据采集上有哪些细节上的不同。考虑到ChatGPT仅仅被用在对话领域,猜测ChatGPT在数据采集上有两个不同:1. 提高了对话类任务的占比;2. 将提示的方式转换Q&A的方式。
- GPT-4
GPT-4相较ChatGPT全方位升级,包括升级多模态模型、支持复杂问题解决、可靠性与安全性提升、推出可预测深度学习堆栈和开源Evals评估框架。
1.多模态模型:支持图片输入,文本能力升级
- 根据OpenAI 官网案例,GPT-4能够发现图片中的异常之处,明白“梗图”中的含义和笑点,甚至能直接阅读并分析带有图片的论文。
- 文本能力方面,GPT-4的表现显著优于现有大型语言模型。GPT-4能够处理超过2.5万字的文本,允许长篇内容创建、扩展对话以及文档搜索和分析等应用场景。

2.支持复杂性问题解决,可靠性与安全性显著提升
- 提升各种专业和学术水准并有较好表现。GPT-4在人类模拟考试中的表现超越GPT-3.5。在没有专门培训的情况下,GPT-4在律师 考试 、LSAT 、GREQuantitative等测试中的得分基本全部高于GPT-3.5。
- GPT-4在语言风格方面得到更新。与具有固定冗长语气和风格的经典ChatGPT不同,开发人员可以通过描述,在系统中规定AI的语言风格,即拥有“自定义”的功能。

- GPT-4在可靠性与安全性方面实现最好结果。
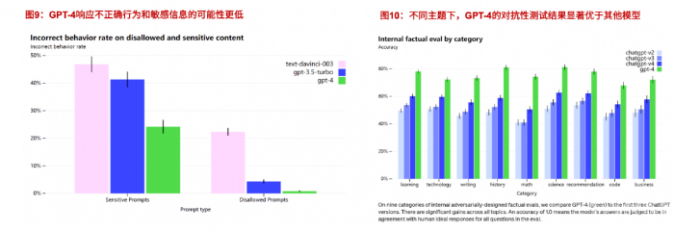
3.推出可预测深度学习堆栈,开源 Evals 评估框架
- Evals可用于分析 GPT-4 等模型的性能来评估其有效性。借助 Evals,程序员可以使用数据集生成问题,评估 OpenAI 模型响应的准确性与各种数据集和模型的功效。
3.2.3 DM(Diffusion Model,扩散模型)
“扩散” 来自一个物理现象:当我们把墨汁滴入水中,墨汁会均匀散开;这个过程一般不能逆转,但是 AI 可以做到。当墨汁刚滴入水中时,我们能区分哪里是墨哪里是水,信息是非常集中的;当墨汁扩散开来,墨和水就难分彼此了,信息是分散的。类比于图片,这个墨汁扩散的过程就是图片逐渐变成噪点的过程:从信息集中的图片变成信息分散、没有信息的噪点图很简单,逆转这个过程就需要 AI 的加持了。

研究人员对图片加噪点,让图片逐渐变成纯噪点图;再让 AI 学习这个过程的逆过程,也就是如何从一张噪点图得到一张有信息的高清图。这个模型就是 AI 绘画中各种算法,如Disco Diffusion、Stable Diffusion中的常客扩散模型(Diffusion Model)。
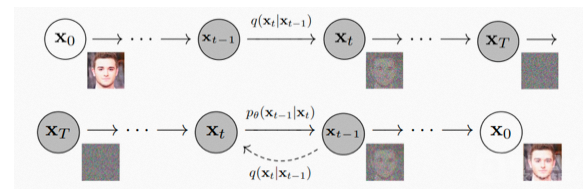
这里仅对Diffusion模型原理进行一个大致介绍,更加细节的推理不做赘述,有兴趣的同学可以自行学习。
3.2.4 CLIP( Contrastive Language-Image Pre-Training,大规模预训练图文表征模型)
大规模预训练图文表征模型用4亿对来自网络的图文数据集,将文本作为图像标签,进行训练。进行下游任务时,只需要提供和图上的concepts对应的文本描述,就可以进行zero-shot transfer。CLIP为CV研究者打开了一片非常非常广阔的天地,把自然语言级别的抽象概念带到计算机视觉里。
图片分类的zero-shot指的是对未知类别进行推理。
CLIP在进行zero-shot transfer时,将数据集中的类别标签转换为文字描述(100个类别就是100个文本描述)
zero-shot CLIP怎么做prediction?
zero-shot prediction:基于输入的图片,在类别描述中检索,找到最合适的类别。
Linear-probe evaluation:通过CLIP的image_encoder得到视觉向量,结合标签做Logistic Regression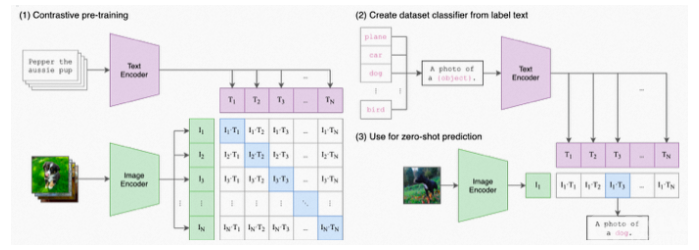
CLIP结构非常简单,将图片分类任务转换成图文匹配任务:
1、用两个encoder分别处理文本和图片数据,text encoder使用Transformer,image encoder用了2种模型,ResNet和Vision Transformer(ViT);
2、encoder representation直接线性投影到multi-modal embedding space;
3、计算两模态之间的cosine similarity,让N个匹配的图文对相似度最大,不匹配的图文对相似度最小;
4、对称的cross-entropy loss;
5、数据增强:对resized图片进行random square crop;
3.2.5 Stable Diffusion
当下AIGC的另一个大热点,AI绘画:只输入文字描述,即可自动生成各种图像。其核心算法-Stable Diffusion,就是上面提到的文字到图片的多模态算法CLIP和图像生成算法DIffusion的结合体。
参考论文中介绍算法核心逻辑的插图,Stable Diffusion的数据会在像素空间(Pixel Space)、潜在空间(Latent Space)、条件(Conditioning)三部分之间流转,其算法逻辑大概分这几步:
1、图像编码器将图像从像素空间(Pixel Space)压缩到更小维度的潜在空间(Latent Space),捕捉图像更本质的信息;
2、对潜在空间中的图片添加噪声,进行扩散过程(Diffusion Process);
3、通过CLIP文本编码器将输入的描述语转换为去噪过程的条件(Conditioning);
4、基于一些条件对图像进行去噪(Denoising)以获得生成图片的潜在表示,去噪步骤可以灵活地以文本、图像和其他形式为条件(以文本为条件即 text2img、以图像为条件即 img2img);
5、图像解码器通过将图像从潜在空间转换回像素空间来生成最终图像。
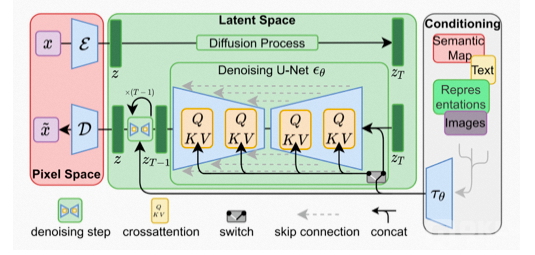
Diffusion和CLIP算法我们上面已经聊过了,潜在空间又是什么?
大家都有自己的身份证号码,前 6 位代表地区、中间 8 位代表生日、后 4 位代表个人其他信息。放到空间上如图所示,这个空间就是“人类潜在空间”。
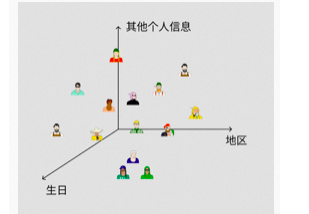
这个空间上相近的人,可能就是生日、地区接近的人。AI 就是通过学习找到了一个”图片潜在空间“,每张图片都可以对应到其中一个点,相近的两个点可能就是内容、风格相似的图片。同时这个 “潜在空间” 的维度远小于 “像素维度”,AI 处理起来会更加得心应手,在保持效果相同甚至更好的情况下,潜在扩散模型对算力、显卡性能的要求显著降低。
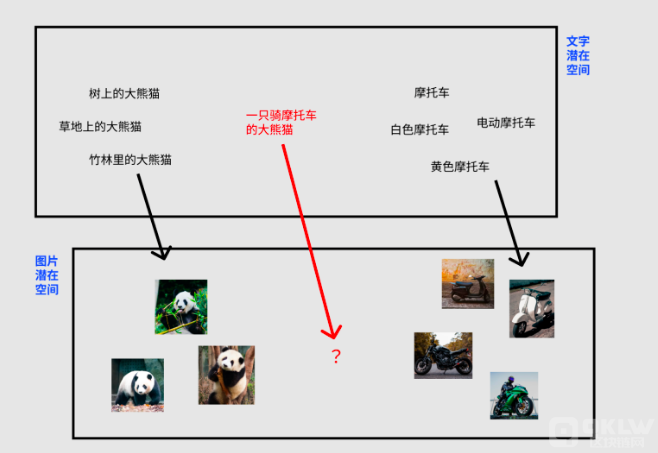
当 AI 建立了“文字潜在空间”到“图片潜在空间”的对应关系,就能够通过文字控制图片的去噪过程,实现通过文字描述左右图像的生成。
3.3 大模型使得AIGC有了更多的可能
- 视觉大模型提高AIGC感知能力
以图像和视频为代表的视觉数据是我们这个时代下信息的主要载体之一,这些视觉信息时刻记录着物理世界的状态,反映着人的想法、观念和价值主张。在深度学习时代,主要是基于深度神经网络模型,比如深度残差网络(ResNet),这类模型往往针对单一感知任务进行设计,很难同时完成多种视觉感知任务。而大模型则可以让AIGC技术解决掉不同场景、环境和条件下的视觉感知问题,并实现鲁棒、准确、高效的视觉理解。近年来基于Transformer衍生出来的一系列大模型架构如Swin Transformer、ViTAE Transformer,通过无监督预训练和微调的范式,在图像分类、目标检测、语义分割、姿态估计、图像编辑以及遥感图像解译等多个感知任务上取得了相比过去精心设计的多种算法模型更加优异的性能和表现,有望成为基础视觉模型(Foundation Vision Model),显著提升感知能力,助力AIGC领域的发展。
- 语言大模型增强AIGC认知能力
作为是人类文明的重要记录方式,语言和文字记录了人类社会的历史变迁、科学文化和知识文化。基于语言的认知智能可以更快加速通用人工智能(AGI)的到来。在如今信息复杂的场景中,数据质量参差不齐、任务种类多,存在着数据孤岛和模型孤岛的问题,深度学习时代对自然语言的处理有着很明显的不足,包括模型设计、部署困难;数据难以复用;海量无标签难以进行数据挖掘、知识提取。谷歌和OpenAI分别提出的大规模预训练模型BERT和GPT,今年来在诸多自然语言理解和生成任务上取得了突破性的性能提升,相信大家现在已经深有感触。
- 多模态大模型升级AIGC内容创作能力
在日常生活中,视觉和语言是最常见且最重要的两种模态,视觉大模型可以构建出人工智能更加强大的环境感知能力,语言大模型则可以学习到人类文明的抽象概念以及认知的能力。如果AIGC技术只能生成单一模态的内容,那么其应用场景将极为有限、不足以推动内容生产方式的革新。多模态大模型的出现,则让融合性创新成为可能,极大丰富AIGC技术可应用的广度。多模态大模型将不同模态的原始数据映射到统一或者相似语义空间中,实现不同模态信号之间的相互理解与对齐。基于多模态大模型,AIGC才能具备更接近于人类的创作能力,并真正的开始展示出代替人类进行内容创作,进一步解放生产力的潜力。
3.4 大模型不是人人玩得起的
大模型门槛比较高,具体表现为参数大、数据大、算力大
参数:语言大模型的参数规模亿级~万亿级(BERT作为baseline),图像大模型参数规模在亿级~百亿级范围。模型参数越大,代表着需要存储模型空间也越变大,需要的成本也就越高。
模型参数是什么?
aX1+bX2=Y,X1和X2是变量,Y是计算结果,a和b是参数,同理,一个神经网络模型,无论规模多大,它都是一个函数,只不过这个函数极其复杂,维度极其多,但依然是由参数、变量来组成,我们通过数据来训练模型,数据就是变量,而参数,就是通过变量的变换,学到的最终的常量。
5年内,模型参数数量从亿级别发展到100万亿级,增长100万倍
数据:模型参数的大幅增长,必然需要更大的数据来训练,否则模型强大的表征能力就会轻易地过拟合。由于标注成本和训练周期的限制,传统有监督的方式将变得不现实,因此无法全用标注好的监督数据,需要利用自监督的方法,挖掘数据中的信息。从18年BERT的33亿词符,到19年XLNet的330亿词符,20年GPT-3的6800亿词符,数据量以十倍速度增长(英文数据集大小也差不多止于此),22年PaLM 使用了7800亿词符训练。

不同大模型预训练数据集规模(大小:GB)的增长对比
算力:尽管“小模型”阶段对算力的要求就一直持续增长,但那个阶段可以说用1张GPU卡可以解决,也算不上太夸张,很多个体,小企业也都可以玩,但是到了超大规模预训练模型阶段,超大的参数、数据带来对算力的要求,是普通玩家难以企及的。就算构建了网络结构,获取到了数据,但是算力不行,也训练不起来。从算力需求的角度看,从GPT的18k petaFLOPs,到 GPT-3的310M petaFLOPs,以及PaLM的2.5B petaFLOPs,更直观的可以看下面这张图。从成本的角度,感受大模型训练对算力成本的吞噬——GPT-3的训练使用了上万块英伟达v100 GPU,总成本高达2760万美元,个人如果要训练出一个PaLM也要花费900至1700万美元。
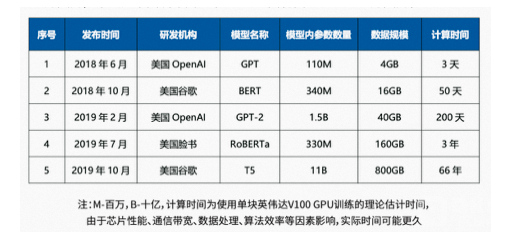
典型的大模型例如GPT BERT GPT-2等的训练时间
四、一些畅想
素材生产大模型:AIGC在素材图片生成已经有了落地成果,如果大模型加持下,其素材生成质量和图像内容理解会不会有一个质的飞跃?利用大模型理解用户动向,对文字素材进行个性化产出?
智能UI大模型:当下智能UI本质上还是规则约束,大模型会不会实现真正的智能?
用户理解大模型:推荐大模型?刻画用户画像和用户动向,统一长尾流量场景模型,预测新疆流用户偏好(真快,都有人发论文了Chat-REC)
阿里版GPT官宣:所有产品都将接入!

4月11日,在2023阿里云峰会上,阿里云推出通义千问大语言模型(LLM),该模型支持多轮交互及复杂指令理解、多模态融合、外部增强API等功能;同时,阿里云推出企业专属大模型产品。
会上,阿里董事会主席兼CEO张勇宣布,阿里所有产品未来将接入大模型全面升级,包括淘宝、天猫、高德地图、菜鸟、饿了么等所有国民级产品。Foundation model仍然在早期,但未来可期:
Most information processing and analysis tasks, and perhaps even things like robotic control, will be handled by a specialization of one of a relatively small number of foundation models. These models will be expensive and time-consuming to train, but adapting them to different tasks will be quite easy; indeed, one might be able to do it simply with natural language instructions.
引用一句Manning大佬的原话,AI模型收敛到少数几个大模型会带来伦理上的风险。但是大模型这种将海量数据中学来的知识应用到多种多样任务上的能力,在历史上第一次地非常地接近了(通用)AI的目标:对单一的机器模型发出简单的指令就做到各种各样的事情。

训练模型是指从给定的训练集中学习模型参数的过程
以便将输入映射到输出。它包括多种不同形式,例如机器学习算法,其中知识和经验被应用到给定的数据集上,来产生特定的结果。当训练模型正确地学习参数时,它可以应用于将新的输入映射到结果。
训练模型一般都是基于损失函数,其中寻找使某个损失函数达到最小值的参数。在最大程度降低损失函数的同时,需要最优化模型,从而最大限度地使事情变得更好。这可以通过多种方式实现,例如,通过梯度下降法进行模型训练,使得梯度下降向量指向最优值,并使梯度更新以最小化损失函数值。梯度下降有多种变体,例如基于批次的梯度下降,使模型参数更新得更快,从而更有效地减少损失函数值。
另一种训练模型的形式是无监督式学习,该算法旨在从海量数据中发现有用的模式,无需事先定义的任何监督。它可以提取层次结构的隐藏模式,甚至可以学习从未出现过的模式。它通过层次聚类或聚类算法建立模型,根据该模型可以为新的输入提供一个分类或聚类。
必须注意的是,训练模型由一元或多元统计模型、决策树、神经网络、支持向量机等多种模型组成。这些模型以不同的方式来处理不同的任务,例如,统计模型用于做预报;决策树用于决策分析;神经网络用于计算;支持向量机用于分类或回归。针对不同的任务,需要采用不同的算法来模拟实际场景,以预测结果。
当模型训练完成时,它可以用于特定的应用中,例如,可以用来预测产品销量、帮助投资者决策以及识别异常值等。最终,训练模型的主要目标是了解我们想要解决的问题,然后使用最有效的参数去拟合训练数据,并使模型尽可能地泛化,从而更好地预测新的数据。
下一篇
香港交易所中文官网
-

- tokenpocket多链钱包
- 2023-07-06
- 45967
- 香港交易所(香港聯合交易所有限公司,HKEX)是位於香港的全球證券市場,通過提供全面而活躍的資源,運用有助於營商及投資者之先進交易場,提供中央及地方層級之融資活動的穩定的基礎;同時...
24小时热点
热点专题

 2400372
2400372 







