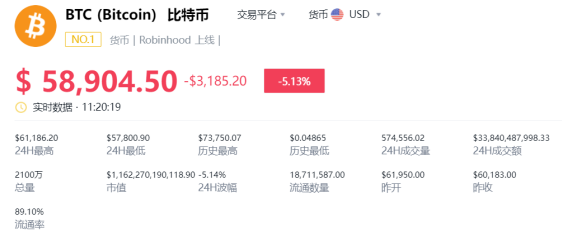
哈希猜大小的原理及实现方式是什么?
-
哈希猜大小,并非传统意义上的“猜测”一个确切的哈希值,因为哈希函数的单向性和不可逆性决定了这几乎是不可能的任务。相反,它更像是一场利用哈希函数的输出特性,如长度固定,分布均匀等,来推测或缩小可能输入范围的智力游戏。在这个过程中,我们尝试通过已知的信息或算法,对哈希值可能展现出的某种模式或特征进行预测或推断。
一、哈希猜大小的原理
哈希猜大小的原理深藏于哈希函数的数学特性之中。哈希函数设计之初就旨在将任意长度的输入数据转换为固定长度的输出(即哈希值),并且这个转换过程应当是单向且难以逆向的。然而,哈希值虽无法直接逆向解析出原始数据,但其分布特性,长度固定等特征却为“猜大小”提供了可能。例如,通过大量样本分析,我们可以发现某些特定类型的输入数据可能倾向于生成具有特定前缀或后缀的哈希值,从而尝试缩小猜测范围。
二、哈希猜大小的实现方式
实现哈希猜大小,通常需要结合多种策略和技术。一种常见的方法是利用统计学和概率论来分析哈希值的分布规律,从而预测特定类型输入可能产生的哈希值特征。此外,随着机器学习和人工智能的发展,一些研究者也尝试使用这些高级算法来训练模型,以更准确地预测哈希值的某些属性。不过,需要强调的是,这些方法的成功率往往受限于哈希函数的复杂性和数据集的多样性,且难以达到百分之百的准确率。
三、哈希猜大小出现的原因
哈希猜大小之所以引起关注,部分原因在于它揭示了哈希函数在保障数据安全的同时,也可能存在的被间接利用的风险。在区块链,密码学等领域,哈希函数被广泛用于验证数据的完整性和真实性。然而,随着技术的不断进步,人们开始意识到,即使哈希函数本身难以被直接破解,但通过对其输出特性的深入分析,仍有可能找到一些间接的利用方式。因此,哈希猜大小的出现,促使人们更加重视哈希函数的选择和使用,力求在保障数据安全与提高系统效率之间找到更好的平衡点。
哈希猜大小作为一种基于哈希函数特性的逆向思维尝试,虽然在实际应用中面临诸多限制和挑战,但它无疑为我们提供了审视哈希函数安全性的新视角。在体验哈希函数带来的便利与安全保障的同时,我们也应保持警惕,理性看待其潜在的风险与不足。通过不断优化哈希函数的设计,加强系统安全防护措施以及提升用户的安全意识,我们可以更好地应对哈希猜大小等挑战,保障数据的安全与系统的稳定运行。

下一篇
哈希游戏玩法介绍,哈希算法游戏攻略内容是什么?
-

- 区块链圈小菜鸡
- 2024-07-03
- 16655
- 哈希游戏是一种基于哈希算法原理设计的数字游戏,玩家通过解决与哈希值相关的谜题或挑战来获取游戏进展或奖励,融合了技术深度与游戏趣味性。那么,哈希游戏的玩法是什么?哈希算法的游戏攻略内容又是什么?
24小时热点
热点专题

 2393784
2393784