哈希值唯一吗?哈希值唯一性的原理是什么?
-
哈希值是通过哈希算法对输入数据进行处理得到的一串固定长度的数值或字符串。这个值通常用于数据的快速查找,验证数据的完整性或作为数据的唯一标识符。那么,哈希值唯一吗?哈希值唯一性的原理又是什么?

一、哈希值的定义与特点
哈希值(Hash Value),又称散列值,杂凑值或消息摘要,是一种通过哈希函数将任意长度的输入数据(称为消息或明文)映射为固定长度的输出数据(称为哈希值或密文)的数值表示形式。这个过程类似于对输入数据进行加密或压缩,但哈希值并不是加密后的数据,而是一种独特的数据标识符。哈希值具有几个显著特点:
1.长度固定,无论输入数据大小如何,输出的哈希值长度都是固定的;
2.单向性,即哈希过程不可逆,从哈希值无法直接恢复原始数据;
3.敏感性,即使输入数据有微小变化,其哈希值也会发生显著改变。
二、哈希值唯一吗
在理想情况下,哈希值的设计目标是追求唯一性,但严格意义上讲,存在较小的碰撞可能性。
所谓“碰撞”,即不同的输入数据产生了相同的哈希值。虽然现代哈希算法如SHA-256,MD5等在设计时都力求降低碰撞发生的概率,但理论上,由于哈希值的长度固定且远小于输入数据的可能性空间,当输入数据量足够大时,碰撞几乎是不可避免的。在实际应用中,由于这种碰撞发生的概率比较低,我们通常认为哈希值具有相对的唯一性。
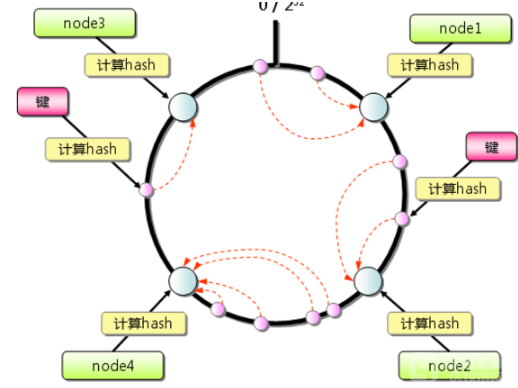
三、哈希值唯一性的原理
哈希值之所以能在很大程度上保持唯一性,主要归功于哈希函数的精心设计。这些函数通过复杂的数学运算,如位运算,模运算,非线性函数等,将输入数据映射到一个看似随机但实则高度分散的哈希空间中。在这个空间里,每个哈希值都像是被精心放置的“点”,而哈希函数则保障了这些点之间的距离足够远,从而减少了碰撞的可能性。
此外,哈希函数的单向性和敏感性也进一步增强了哈希值的唯一性。单向性意味着哈希过程不可逆,这避免了通过哈希值反向推导出原始数据的可能性;而敏感性则保障了即使输入数据有微小变化,其哈希值也会发生显著改变,从而增加了不同输入产生不同哈希值的概率。
四、为什么会出现哈希值的唯一性?
哈希值的唯一性并非自然存在,而是人类智慧的结晶。它是为了满足特定需求(如数据完整性验证,快速查找等)而设计的。通过复杂的哈希算法,我们能够将海量的输入数据高效地转换为简洁且相对唯一的哈希值,从而简化了数据处理和存储的过程。同时,哈希值的唯一性也为数据的安全性和完整性提供了有力保障。
虽然哈希值在大多数情况下可以被视为相对唯一,但我们必须认识到其潜在的碰撞风险。在涉及高安全性要求的场景中,如区块链技术中的交易验证,密码存储等,我们应选择较强且经过充分验证的哈希算法,以降低碰撞发生的可能性。此外,随着量子计算等新技术的发展,传统哈希算法的安全性也面临着新的挑战。


下一篇
什么是哈希值?哈希值与加密货币有什么关联?
-

- 区块链网快讯
- 2024-07-03
- 8666
- 哈希值是通过哈希函数计算得出的固定长度的数据摘要,用于唯一标识输入数据。它起源于密码学和计算机科学,用于验证数据完整性和安全性,成为现代加密货币和信息安全领域的核心技术之一。
24小时热点
热点专题

 2393784
2393784