
“封装复杂性” vs. “系统复杂性”
-
Vitalik:协议设计中的“封装复杂性” vs. “系统复杂性”
以太坊协议设计的主要目标之一是最小化复杂性:使协议尽可能简单,同时仍然使区块链能够做好一个有效的区块链网络需要做到的事情。以太坊协议在这方面还远远不够完美,特别是因为它的很多部分都是在 2014-16 年设计的,当时我们对它的理解要少得多,但我们仍然在尽可能地积极努力降低复杂性。
然而,这个目标的挑战之一是复杂性很难定义,且有时,你必须在两个引入不同种类复杂性和具有不同代价的选择之间进行权衡。我们如何比较?
有一个强大的智能工具可以让我们对复杂性进行更细致的思考,那就是区分我们所谓的封装复杂性 (encapsulated complexity) 和系统复杂性 (systemic complexity)。
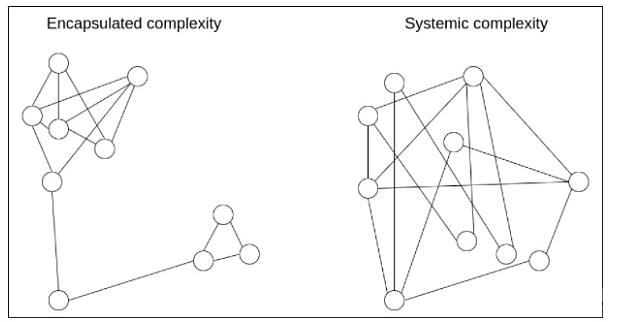
当一个系统的子系统内部复杂,但向外部呈现一个简单的“接口” (interface) 时,就是出现了「封装复杂性」。当系统的不同部分甚至不能被清晰地分开,并且相互之间有复杂的交互时,「系统复杂性」就出现了。
以下是几个例子。
BLS 签名 vs. Schnorr 签名
BLS 签名和 Schnorr 签名是两种常用的可由椭圆曲线构成的加密签名方案。
BLS 签名在数学上看起来非常简单:
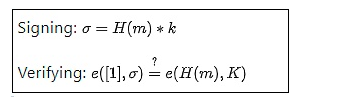
H 是一个哈希函数,m 是消息,k 和 K 是私钥和公钥。到目前为止,很简单。然而,真正的复杂性隐藏在 e 函数的定义中:椭圆曲线配对(elliptic curve pairings),这是所有密码学中最难以理解的数学部分之一。
现在,我们来看看 Schnorr 签名。Schnorr 签名只依赖于基本的椭圆曲线。但是签名和验证逻辑有点复杂:

所以…哪种类型的签名“更简单”?这取决于你在乎什么!BLS 签名具有巨大的技术复杂性,但复杂性都隐藏在 e 函数的定义中。如果你把 e 函数看作一个黑盒,BLS 签名实际上是非常简单的。另一方面,Schnorr 签名的总体复杂性较低,但有更多的部分,能以一种微妙的方式与外部世界互动。
例如:
-
进行 BLS 多签 (两个密钥 k1 和 k2 的组合签名) 很简单:只需 σ1+σ2。但是 Schnorr 多签名需要两轮交互,并且需要处理一些棘手的 Key Cancellation 攻击。
-
Schnorr 签名需要生成随机数,BLS 签名不需要。
椭圆曲线配对通常是一个强大的“复杂性海绵”,因为它们包含大量封装复杂性,但使解决方案具有更少的系统复杂性。这也适用于多项式承诺领域:将 KZG 承诺 (需要配对) 的简单性与更复杂的内积证明 (inner product arguments,不需要配对) 的内部逻辑进行比较。
密码学 vs. 加密经济学
在许多区块链设计中出现的一个重要设计选择是密码学 (cryptography) 与加密经济学 (cryptoeconomics) 的比较。这 (比如在 Rollups 中) 常常是在有效性证明 (即 ZK-SNARKs) 和欺诈证明之间做出选择。
ZK-SNARKs 是复杂的技术。虽然 ZK-SNARKs 工作原理背后的基本思路可以在一篇文章中解释清楚,但实际上实现一个 ZK-SNARK 来验证一些计算涉及到比计算本身多很多倍的复杂性 (因此,这就是为什么用于 EVM 的 ZK-SNARKs 证明仍在开发中,而用于 EVM 的欺诈证明已经在测试阶段)。有效地实现一个 ZK-SNARK 证明涉及到了对特殊目的进行优化的电路设计、使用不熟悉的编程语言以及许多其他挑战。另一方面,欺诈证明本身就很简单:如果有人提出挑战,你只需直接在链上运行计算。为了提高效率,有时会添加一个二进制搜索方案,但即使这样也不会增加太多的复杂性。
虽然 ZK-SNARKs 很复杂,但它们的复杂性是封装复杂性。另一方面,欺诈证明的相对较低的复杂性,是系统复杂性。以下是欺诈证明引入的一些系统复杂性的例子:
-
它们需要谨慎的激励工程来避免验证者的困境。
-
如果在达成共识的情况下完成,它们需要为欺诈证明提供额外的交易类型,同时还要考虑到如果许多参与者同时竞相提交欺诈证明会发生什么。
-
它们依赖于一个同步网络。
-
它们允许审查攻击 (censorship attacks) 也被用来进行盗窃。
-
基于欺诈证明的 Rollups 要求流动性提供者支持即时提款。
由于这些原因,即使从复杂性的角度来看,基于 ZK-SNARKs 的纯加密解决方案也可能是长期安全的:ZK-SNARKs 有着更复杂的部分,这是一些人在选择 ZK-SNARKs 时必须考虑到的;但 ZK-SNARKs 有着更少的悬空警告,这是每个人都必须考虑到的。
各种例子
-
PoW (中本聪共识):较低的封装复杂性,因为该机制非常简单和容易理解,但有着更高的系统复杂性 (如自私挖矿攻击)。
-
哈希函数:较高的封装复杂性,但有着非常容易理解的属性,因此系统复杂性很低。
-
随机洗牌算法:洗牌算法既可以是内部复杂 (比如 Whisk),但却能够确保强大的随机性,且易于理解;也可以是内部简单,但却能够产生较弱且难以分析的随机性属性 (比如系统复杂性)。
-
矿工提取价值 (MEV):一个强大到足以支持复杂事务 (complex transactions) 的协议在内部可能相当简单,但那些复杂的事务可能会对协议的激励机制产生复杂的系统影响,因为它们会以非常不正常的方式提议区块。
-
Verkle 树:Verkle 树确实有一些封装复杂性,实际上比普通的 Merkle 哈希树要复杂得多。然而,从系统上讲,Verkle 树提供了与键值 (key-value) 映射完全相同的相对干净和简单的界面。主要的系统复杂性“泄漏” (leak) 是攻击者操纵 Verkle 树使一个特定值有一个非常长的分支 (branch) 的可能性;但 Verkle 树和 Merkle 树的风险是相同的。
我们如何权衡呢?
通常,封装复杂性较低的选择也是系统复杂性较低的选择,因此有一个选择显然更简单。但在其他时候,你必须在一种复杂性和另一种复杂性之间做出艰难的选择。在这一点上应该清楚的是,如果是封装复杂性,那么其危险性就会更低。一个系统复杂性带来的风险不是一个简单的规范长度的函数;规范中一个 10 行代码的小片段与其他部分相互作用会比 100 行代码的函数更复杂,否则就会被视为一个黑盒。
然而,这种偏好封装复杂性的方法存在局限性。任何一段代码中都可能出现软件 bugs,当代码越来越大时,出现错误的概率接近 1。有时,当你需要以意想不到的新方式与子系统交互时,最初的封装复杂性可能会变成系统复杂性。
后者的一个例子是以太坊当前的两级状态树 (two-level state tree),其特征是帐户对象树,其中每个帐户对象依次有自己的存储树。
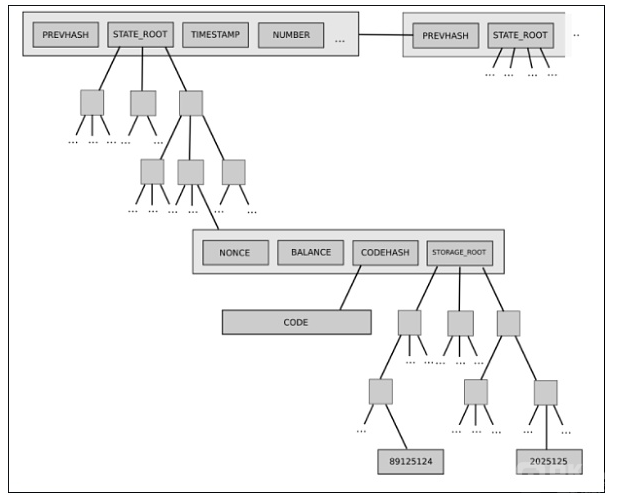
这个树结构是复杂的,但在一开始,这种复杂性似乎被很好地封装:协议的其余部分作为可读写的键/值存储与树交互,所以我们不必担心树是如何构造的。
然而,后来,这种复杂性被证明具有系统性影响:帐户拥有任意大的存储树的能力意味着没有办法可靠地期望某个特定的状态部分 (例如。“所有以 0x1234 开头的帐户”) 具有可预测的大小。这使得将状态分割成多个部分变得更加困难,使同步协议的设计和分布存储进程的尝试变得更加复杂。为什么封装复杂性会变成系统性的?因为 interface 改变了。解决方法是什么?目前转向 Verkle 树的提议还包括转向一个均衡的单层树设计。
最终,在任何给定的情况下,哪种类型的复杂性更受欢迎是一个没有简单答案的问题。我们所能做的最好的事情是适度地支持封装复杂性,但不要太多,并在每个具体的情况下演练我们的判断。有时候,牺牲一点系统复杂性来极大地降低封装复杂性确实是最好的做法。其他时候,你甚至会误判什么是封装的,什么不是。每种情况都是不同的。
-





24小时热点










热点专题

 5292806
5292806





